Paperless-ngx, Teil 17: Unterordner des consume-Verzeichnisses nutzen

Der consume-Ordner von Paperless-ngx wurde in Teil 3 beschrieben. Hier legt z. B. ein Scanner die Dateien ab, die von Paperless-ngx „aufgesaugt“ und ins System integriert werden. Anschließend können Tags, Speicherorte usw. über die Weboberfläche zugewiesen werden.
Es gibt aber die zusätzliche Möglichkeit, mit Unterordnern innerhalb des consume-Verzeichnisses zu arbeiten. Prinzipiell kann darin die gleiche Verzeichnisstruktur abgebildet werden, die man auch sonst auf seinen Speichermedien nutzt.

Der Vorteil der consume-Ordner liegt darin, dass dort gespeicherte Dateien von Paperless-ngx mit einem Tag versehen werden können, der eine weitere Automatisierung erlaubt. Dazu gleich noch mehr.
Inhalt
Unterordner gezielt „befüllen“
Die verschiedenen Möglichkeiten, den consume-Ordner in seinen „Haupt-PC“ einzuhängen, wurden bereits beschrieben (Samba-Verzeichnis in Windows, Syncthing-Tool usw.). Auf den gleichen Wegen lassen sich Dateien mühelos direkt an die Unterordner übergeben. Sofern man einen Dokumentenscanner hat, können dessen Funktionen meist mit entsprechenden Angaben konfiguriert werden, so dass ein frischer Scan ebenfalls an einen bestimmten Unterordner auf Knopfdruck übergeben wird.

Ebenso erlauben eine Reihe von Scanner-Apps, Ordner als Ziele einzurichten. Oder man verwendet auf seinen Geräten Nextcloud. Damit kann ein Sync zwischen den consume-Ordnern auf dem Raspberry Pi und den Nextcloud-Ordnern auf seinen Geräten eingerichtet werden.

Anweisungen für die Konfigurationsdatei
Unsere docker-compose.yml-Datei muss nun lediglich um 2 Zeilen ergänzt werden (im Abschnitt „environment:“ – auf die Einrückung achten oder alternativ in die *.env-Datei aufnehmen).
Zunächst aktivieren wir die Verarbeitung von Unterordnern:
PAPERLESS_CONSUMER_RECURSIVE=trueWeiterhin sollen die Namen der Unterordner als Schlagwörter für jeweiligen Dokumente zugewiesen werden:
PAPERLESS_CONSUMER_SUBDIRS_AS_TAGS=trueDas war es auch schon. Speichert man nun beispielsweise eine Datei in „consume/Familie“, so taucht diese anschließend in Paperless-ngx mit dem Tag „Familie“ auf.

Automatisierung konfigurieren
Das Dokument ist nach dem „Aufsaugen“ durch Paperless-ngx aus dem Unterordner verschwunden. Paperless-ngx soll es aber direkt innerhalb seiner eigenen Speicherstruktur („originales“ und „archive“) in namensgleiche Ordner verschieben, ohne dass wir einen zusätzlichen Aufwand damit haben. Ich werde dazu hier ein einfaches Beispiel nehmen – wie komplex man Speicherorte in Paperless-ngx mit Platzhaltern konfigurieren kann, das habe ich in Teil 4 und Teil 14 der Serie ausführlich beschrieben.
Multiple Speicherorte per Platzhalter einrichten
Selbst wenn viele Unterordner vorhanden sind, so genügt es – dank Platzhaltern – 1 Speicherort und 1 Arbeitsablauf einzurichten.
Zunächst ein Beispiel für den Speicherpfad. Mit „{created_year}/{tag_list}/{title}“ erfolgt eine Zuordnung in das aktuelle Jahr, das die endgültigen Unterordner aufnimmt. Also z. B. „2024/Familie/standesamt.pdf“ oder „2024/Rechnung/anbau.pdf“ usw. „{tag_list}“ würde eigentlich für eine Liste aller Schlagwörter stehen, die ein Dokument aufweist. Aber Paperless-ngx vergibt nur 1 Schlagwort = Name des Unterordners. Somit bleibt es also bei einem kurzen Pfad.

Arbeitsablauf definieren
Der „Auslöser“ ist recht einfach gehalten: Der Ablauf wird aktiviert, wenn ein Dokument hinzugefügt wird – aber nicht, wenn lediglich ein Schlagwort „per Hand“ zugewiesen wird (es kann ja sein, dass ich später mal den Tag „Rechnung“ vergeben möchte, das Dokument aber im Pfad „Steuer“ verbleiben soll.) Weiterhin werden die Namen der Unterordner in Form von Tags eingetragen.
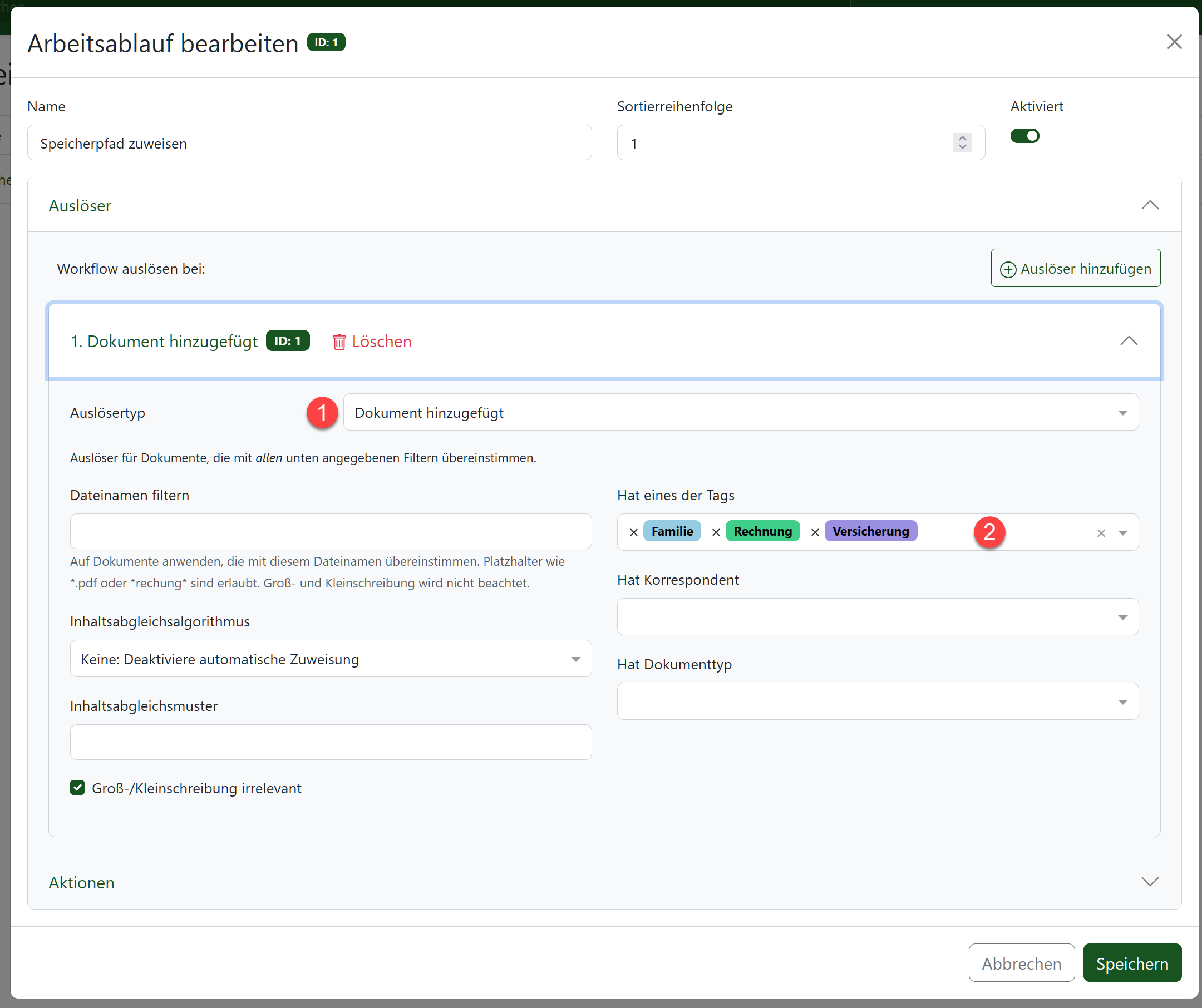
Noch einfach kann die auszulösende Aktion definiert werden: Hier wird einfach der eben konfigurierte Speicherpfad zugewiesen. Fertig.
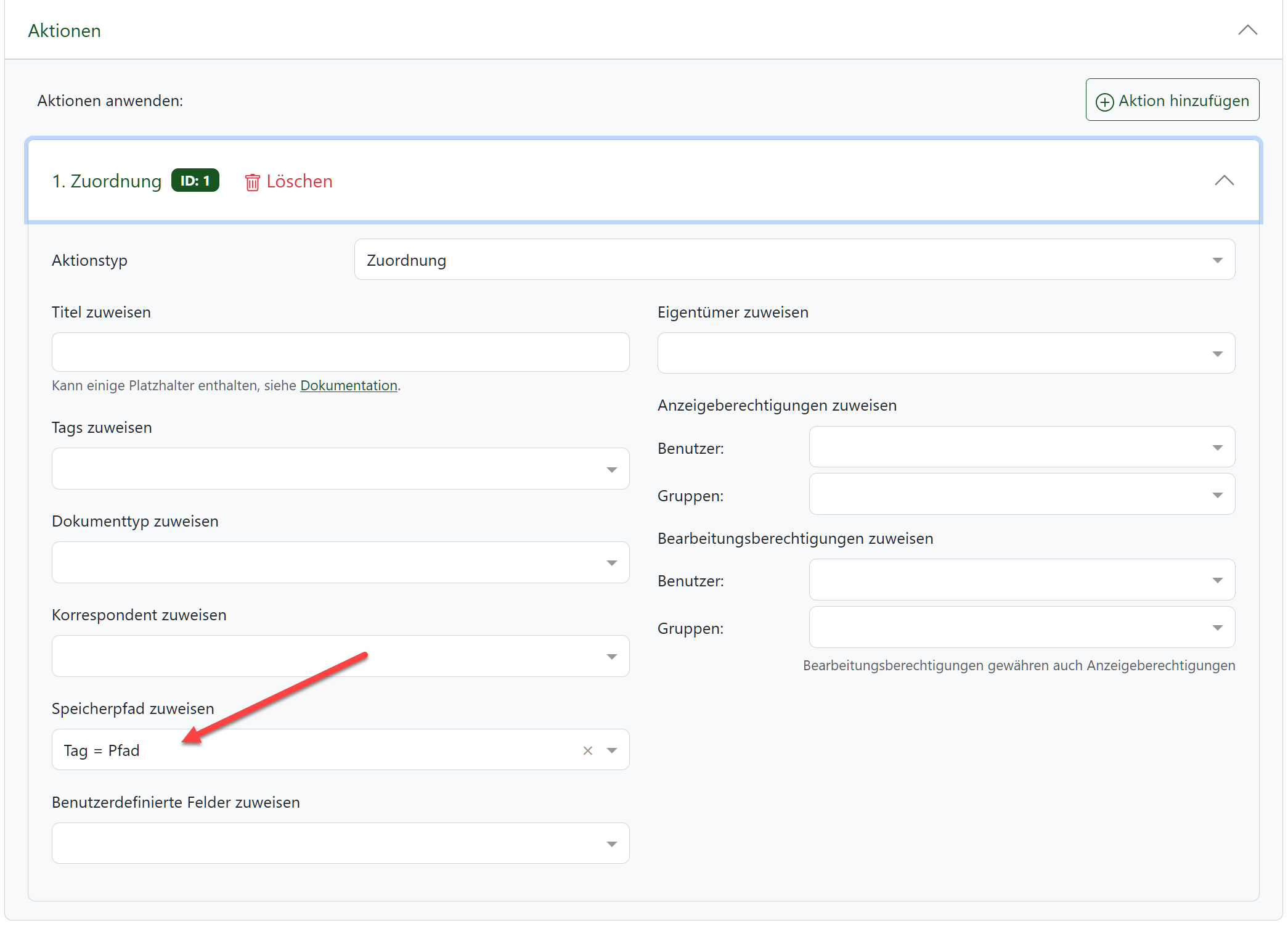
Auf diese Weise lassen sich noch komplexere Vorgänge abbilden: Für die einen Dokumente kann es Verzeichnisse mit einer Monatsstruktur geben (2024/01, 2024/02, 2024/03), bei anderen genügt ein „Sammelverzeichnis“ ohne weitere Unterordner („Ideen“, „Archiv“). Wie immer gilt: Die Sache sollte nicht zu kompliziert werden. Lieber mit wenigen Ordnern arbeiten, dann behält man leichter die Übersicht. Zudem hat man die tolle Suchfunktion plus Tags plus … plus … plus – so dass Paperless-ngx ohnehin weit mehr Möglichkeiten hat, als man dies von seinem Dateimanager gewohnt ist.
Hier noch ein kurzes Video zum Ablauf:
Bisherige Teile der Paperless-ngx-Serie:
Teil 1: Ausführlicher Überblick
Teil 2: Suche & Tags
Teil 3: consume-Ordner – Einsatz von Scannern
Teil 4: Speicherpfade konfigurieren
Teil 5: Installation auf dem Raspberry Pi
Teil 6: Neue Funktionen in Version 2
Teil 7: Dokumente unterwegs über das eigene Modem abrufen
Teil 8: Exportfunktion nutzen
Teil 9: Update durchführen
Teil 10: Das Rundum-sorglos-Backup
Teil 11: Mail-Abruf mit vielen Extras
Teil 12: Mein Alltag mit Paperless-ngx
Teil 13: Ein Quanten-Code für das Papier-Archiv
Teil 14: Automatisierte Ablage auf Speicherpfaden
Teil 15: Neue Funktion für das Verbinden und Trennen von Dokumenten
Teil 16: Dashboard, smarte Widgets und erweiterte Ansichten
Teil 17: Unterordner des consume-Verzeichnisses nutzen
Teil 18: Paperless-ngx auf Synology/NAS ohne Docker nutzen
Teil 19: Praxisbeispiel – kleine Hausverwaltung
Teil 20: Dokumente per Mail aus dem Heimnetz versenden
Teil 21: Die 1-Klick-Sicherung mit allem Drum und Dran
Teil 22: Update der Datenbank – super-simpel
Teil 23: Neuer PDF-Editor
Teil 24: Der Mega-All-in-One-Befehl für die Sofortinstallation
Teil 25: Der Briefmarken-PC für die Weitergabe


Das könnte dich ebenfalls interessieren
Der eigene E-Book-Server für Tolino & Co.

PDF-Sammelmappen automatisiert erzeugen – Teil 1

8 Kommentare
Andreas
Hallo,
Der Absatz mit Tags = ordnerstruktur erstellen lassen funktioniert bei mir einwandfrei. Doch wenn man mehrere Unterordner hat,
Dann gefallen mir 2 Dinge nicht.
1.) Die Tags werden bei dem Dokument sortiert. Sprich nicht wie die Ordner erstellt wurden. Wenn man nun den „speicher Ort“ ansieht sieht es etwa so aus:
Unterunterorder. Ordner. Unterordner
Warum sortiert er die Tags.
Ordner. Unterordner. Unterunterorder wäre die richtige Struktur.
2.) Warum kann man der {tag-list} nicht mitgeben, welches Zeichen es als Trenner verwendet. Ich würde gerne anstelle des „.“ den „\“ verwenden, den dann könnte man ja die Ordnerstruckturen auch am speicher Ort (nicht das consumer Verzeichnis) abbilden.
Danke schon mal für eure Antworten
Andreas
Herbert
Zu 1. Mit Unter-Unter-Ordnern habe ich noch nicht gearbeitet. Wenn das für Dich wichtig ist, dann könntest Du bei der Namensvergabe der Unterordner auf eine bestimmte Reihenfolge achten.
Zu 2. Warum die Entwickler diese Variante nicht einbauen, das kann ich nicht beantworten, da ich keiner bin. Am besten in deren Forum nachfragen.
Simon
Ich hab mir überlegt wenn man auf die Startseite von Paperless-NGX kommt und dort gleich Ordner von den Themen in den man die Aktuellen Sachen drine speichert dann wären alle Dokumente in dem Programm in einem Ordner ist doch dann Übersichtlicher so kann man Beispiel sagen ich geh auf den Ordner Schule und finde da alle Dokumente von meiner Schule aufgelistet so das die Bildlich getrennt sind von den anderen Dokumenten.
ist das umsetzbar?
Herbert
Nein, Ordner auf der Startseite gibt es nicht. Du kannst Mittel wie die Speicherpfade, Tags usw. definieren – das geht schon auch in diese Richtung, ist aber nicht 1:1, was Du wohl da haben möchtest.
Achim Zweygarth
Hallo Herbert,
besten Dank für die wirklich umfassende und ausführliche Paperless-NGX Anleitung für den Raspi.
Läuft bei mir mit inzwischen >1300 Dokumenten und >5Mio. Zeichen bestens.
Nun habe ich vom Steuerberater pdf-Dokumente erhalten, die eben meine digitale Signatur enthalten und die von Paperless nicht gefressen werden. Dazu gibt es auch zahlreiche Lösungsvorschläge im Netz. Ich habe allerdings keine gefunden die sich auf Raspi-Installationen beziehen. Da dies offenbar öfters für Verdruß sorgt, wäre es toll, wenn Du das hier thematisieren könntest. (Oder ist bereits geschehen und google hat bei mir versagt??)
Ich habe ein wenig versucht mit der docker-compose.yml zu spielen und den letzten der drei gefundenen Tags eingefügt. Hat aber bloß Fehlermeldungen erzeugt. Ich bin mit dem Syntax nicht vertraut und stochere hier im Finsteren. Es scheint Unterschiede bei Portainer, Docker… Installationen zu geben. Wäre toll, wenn Du da eine Lösung bieten könntest.
Viele Grüße
Achim
{„invalidate_digital_signatures“: true}
PAPERLESS_OCR_USER_ARGS=“{\“invalidate_digital_signatures\“: true}“
PAPERLESS_OCR_USER_ARGS: ‚{„invalidate_digital_signatures“: true}‘
und die eigentliche Fehlermeldung:
Error occurred while consuming document xyxyxyxyx_signiert.pdf: DigitalSignatureError: Input PDF has a digital signature. OCR would alter the document, invalidating the signature.
BS und Paperless uptodate
Herbert
Wenn man Paperless-ngx auf dem Raspberry Pi so installiert hat, wie ich es in meiner Artikel-Serie beschrieben habe, sollte die Lösung dafür sein:
In die *.env oder *.yml Datei folgende Zeile eintragen:
environment:
PAPERLESS_OCR_USER_ARGS: ‚{„invalidate_digital_signatures“: true}‘
Alternativ kann man auch eine umfangreichere Anweisung eintragen:
environment:
PAPERLESS_OCR_USER_ARGS: ‚{„invalidate_digital_signatures“: true,“continue_on_soft_render_error“: true}‘
Danach neu starten:
docker compose down
docker compose up -d
Hans
Moin,
ich habe die Docker Version, wie in Kapitel 24 erläutern, auf einem Pi installiert.
Aber das scannen aus Unterverzeichnissen des consume Verzeichnises klappt nicht.
Ich habe den Eintrag
PAPERLESS_CONSUMER_RECURSIVE=true
in der docker-compose.yml eingetragen und den Pi neu gestartet.
Die Dateien aus dem consume Verzeichnis werden verarbeitet, die aus den Unterverzeichnissen nicht.
Die Rechte habe ich geprüft, da ist alles erlaubt.
Woran kann das liegen ??
Herbert
In solchen Fällen hilft es oft, wenn man den Container kurz stoppt und wieder neu startet.