Paperless-ngx Teil 2: Suche & Tags

Mit Teil 1 der kleinen Serie über Paperless-ngx sollte ein erster Überblick gegeben werden: verschiedene Ansichten, Abruf von Dokumenten, Eintrag von zusätzlichen Informationen usw. Jetzt werden einzelne Funktionen genauer unter die Lupe genommen.
Inhalt
Rund um Tags
Zunächst ein kurzer Hinweis: Zu Beginn der Arbeit mit Paperless-ngx ist man versucht, sehr viele Tags zu vergeben. Das ist eigentlich nicht notwendig, denn die sehr schnelle Volltextsuche führt meist auch so zum Erfolg. Die Stärken von Tags liegen auf einem anderen Gebiet, dazu weiter unten mehr.
Standard-Tags
Neue Tags können direkt bei der Aufnahme neuer Dokumente erstellt bzw. zugewiesen werden. Oder mit dem entsprechenden Menüpunkt in der Seitenleiste:

Der Button „Dokumente“ bedeutet, dass man sich sofort alle Dateien anzeigen lassen kann, die mit diesem Tag versehen wurden. Text, Icons und Farben lassen sich recht einfach anpassen. Die Farben sind so gewählt, dass sie auch beim Dunkel-Modus gut zu erkennen sind.

Ein Tag kann jederzeit umbenannt werden – die Änderungen übertragen sich sofort auf alle Dokumente. Der geänderte Tag muss also nicht per Hand neu zugewiesen werden.
Sonder-Tag für den Posteingang
Nimmt man neue Dokumente in das Archiv auf, so kann das System diesen einen speziellen Tag automatisch zuweisen. Damit fallen die Neuzugänge besser auf – und man kann sie auch in einem Widget auf der Startseite anzeigen lassen.

Man kann diese Funktion aber auch „temporär“ umfunktionieren: Wenn man z.B. gerade die Steuerunterlagen der letzten 3 Monate in das Archiv aufnehmen möchte, so kann man einen Posteingangs-Tag definieren „Steuer 2023“. Nach der Aufnahme löscht man wieder den Haken bei diesem Tag.
Auto-Tags
Paperless-ngx kann den Inhalt der Dokumente analysieren und selbst Tags vergeben. Der einfachste Fall ist, dass man über ein klares Kennzeichen verfügt: ein bestimmter Absender, eine Kundennummer oder ein eindeutiges Stichwort. So kann etwa der Kontoauszug der Bank X einen anderen Tag zugewiesen bekommen, als dies bei Bank Y der Fall ist. Im folgenden Beispiel weist Paperless dem Schriftverkehr der Elektrizitätswerke automatisch den Tag „E-Werk“ zu:

Kriterium ist hier die Kundennummer „AB-654321“. Diese wurde bei der Definition des Tags „E-Werk“ eingetragen:

Der so definierte Tag wird bei einer Neu-Aufnahme eines Dokuments vergeben. Sollte man bereits 10 frühere Anschreiben im Archiv haben, so ist das auch kein Problem: Man sucht nach der Kundennummer und weist den gefundenen Dokumenten in einem Rutsch den gewünschten Tag zu.

Im Menü werden eine Reihe von weiteren Automatisierungsmöglichkeiten gezeigt. Das System lernt von Dokument zu Dokument dazu.
Suchfunktion
Standard-Suche
Die Suche bei Paperless-ngx ist richtig, richtig gut! Sie funktioniert praktisch in Echtzeit. Viele werden unter Windows das Suchtool „Everything“ kennen. Damit findet man auch bei sehr großen Speichermedien die Dateien in Sekundenbruchteilen. Das gilt auch für Paperless. Aber eben nicht nur für die Dateinamen. Durch die OCR-Erfassung wandert ja der gesamte Inhalt eines Dokuments in die Datenbank. Und Begriffe aus einer Datenbank zu fischen, nun, das ist sehr anspruchslos. Daher ist der Suchvorgang auch auf einem günstigen Raspberry Pi super-schnell. [Ja, Windows kann auch Textinhalte vollständig indizieren – aber mit den Ergebnissen war ich zumindest auf diesem System nie wirklich zufrieden (MacOS ist da besser – aber ich nutze nun mal Windows)].
Paperless-ngx bildet intern einen Score der gefundenen Ergebnisse – versucht also, jene Dokumente, die besonders gut der Suche entsprechen, nach oben zu schieben.
Wie auch immer: Man tippt einen beliebigen Begriff ein – und alle gefundenen Dokumente werden umgehend eingeblendet.
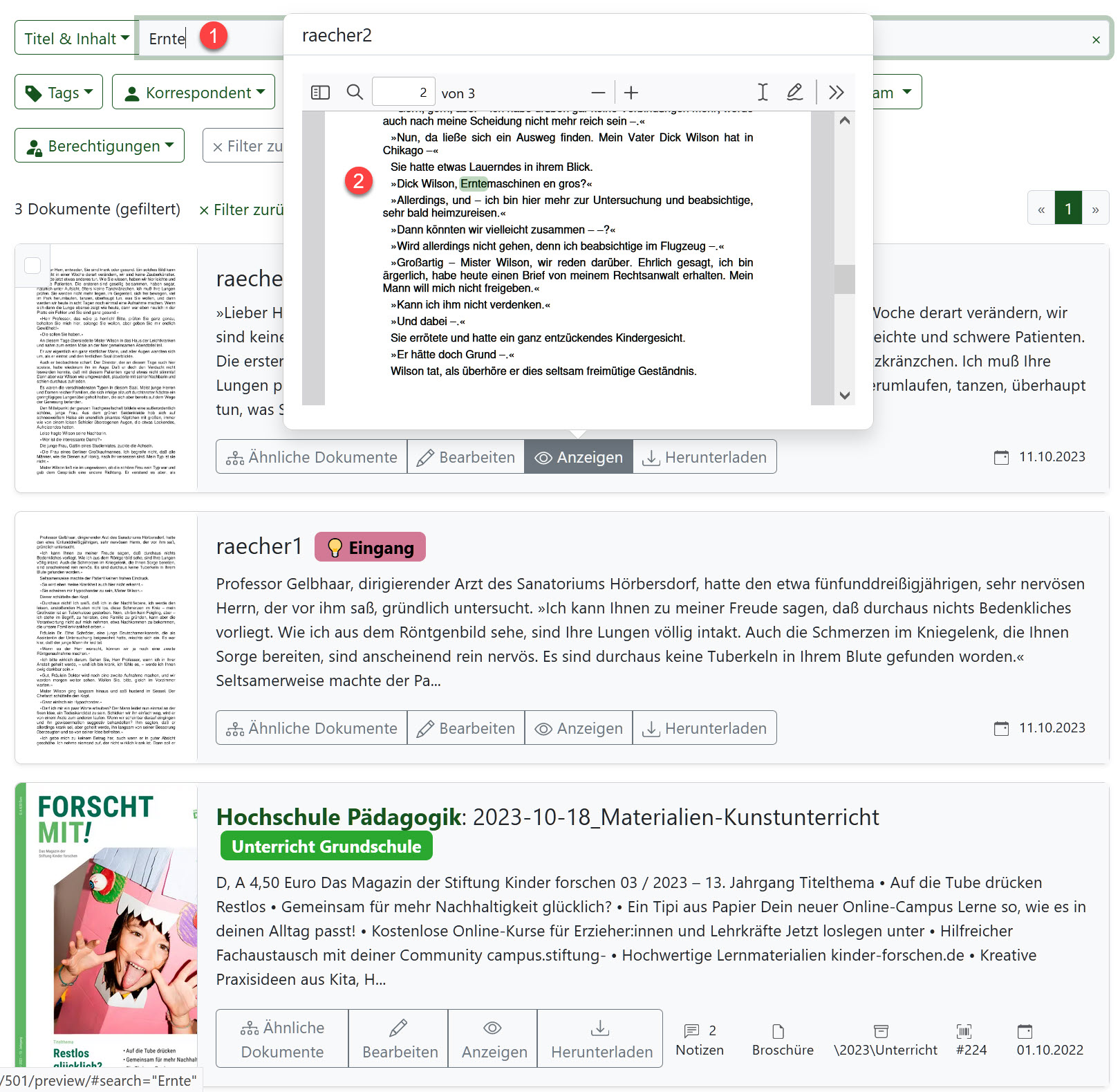
Am Beispiel (Text aus „Der Rächer der Enterbten“, Projekt Gutenberg) sieht man, dass man in der Liste der Resultate alle relevanten Merkmale sofort vor Augen hat. Es wurden drei Dokumente gefunden – evtl. erkenne ich schon Cover-Thumbnail, welches Dokument ich suche. Ansonsten kann ich bei jedem Dokument kurz über das „Anzeigen“-Icon mit dem Mauszeiger fahren – ich erhalte die Fundstelle samt Kontext angezeigt. Klicke ich auf das Icon, erscheint das vollständige Dokument, der Cursor springt zur ersten Fundstelle – aber auch alle weiteren Fundstellen innerhalb des gleichen Dokuments sind farblich markiert.

Date-Picker
Bei größeren Archiven kann die Suche innerhalb eines Datumsbereichs sehr hilfreich sein. Paperless-ngx stellt dafür einen recht guten Date-Picker zur Verfügung, der die Arbeit für diese Art der Suche deutlich erleichtert:
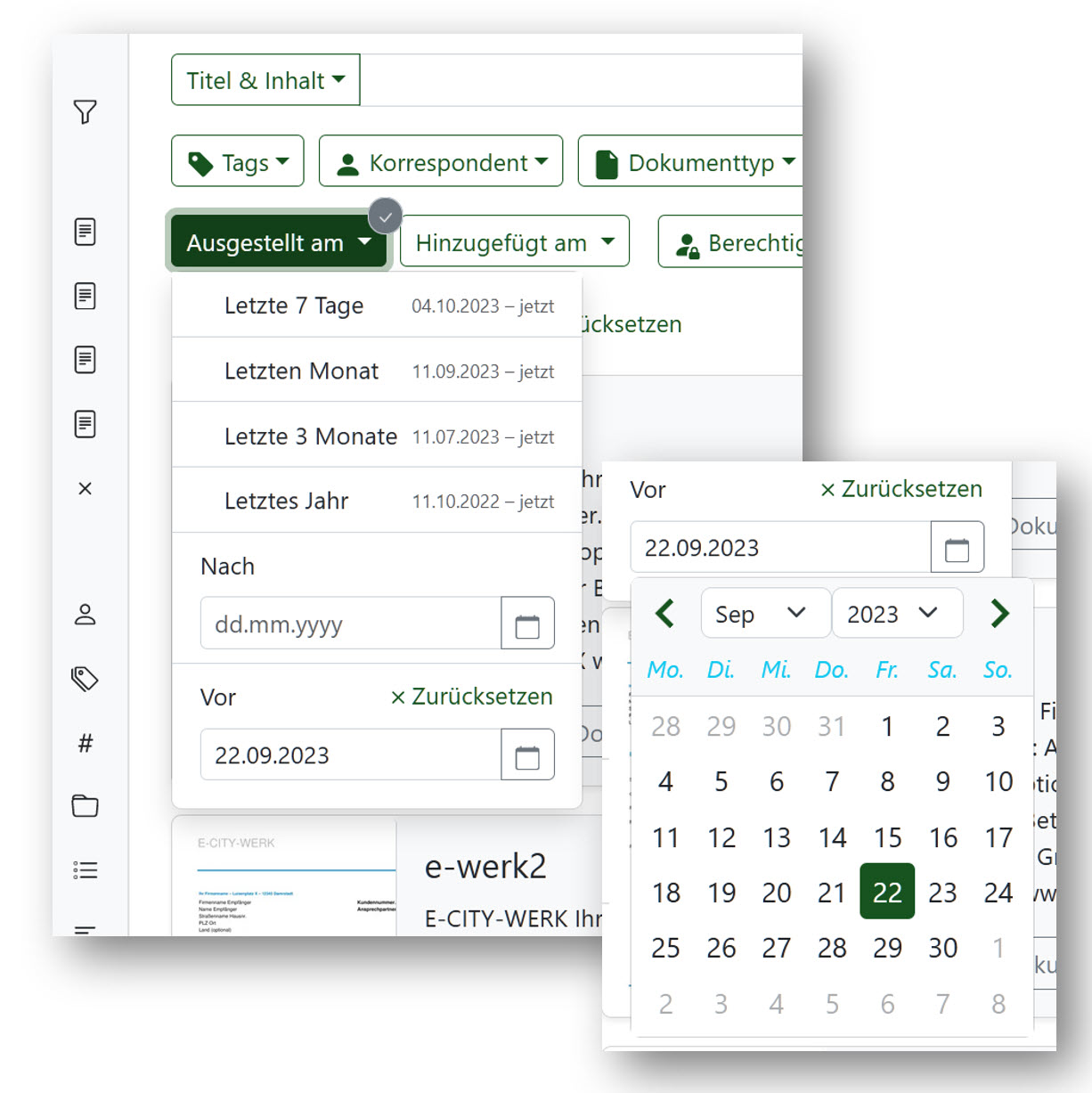
Die Suche ist in den beiden Feldern „Ausgestellt am“ und „Hinzugefügt am“ möglich. „Ausgestellt am“ wird bei der Aufnahme eines Dokumentes von Paperless ausgelesen, so dass man das Feld nicht unbedingt von Hand ausfüllen muss. Das Auslesen klappt auch bei Standardpost ganz gut, da die Position des Datums in Briefen einigermaßen standardisiert ist. Bei anderen Dokumenten nimmt Paperless ein Datum, das darin auftaucht – da wird man gelegentlich einen Blick drauf werfen müssen, ob man damit zufrieden ist. Ganz nützlich finde ich persönlich die „vor-dem“-Suche, da ich meist in chronologischen Abschnitten denke. Wenn ich also einen Beleg aus den Herbst-Semesterferien 2022 suche, so kann ich damit einfach „suche vor 1.10.22“ durchführen. Sicher auch für manchen Quartalsbericht nützlich oder für Steuererklärungen.
Kombinierte Suche
Alle Feldinhalte lassen sich mit der Textsuche kombinieren. So kann ich etwa nur in einem bestimmten Verzeichnispfad suchen. Oder nur in Dokumenten, die bestimmte Tags aufweisen. Das vorherige Beispiel erzielte 3 Resultate bei der einfachen Textsuche. Wenn nun ein Tag ausgewählt wird, so erscheint nur noch 1 Ergebnis:
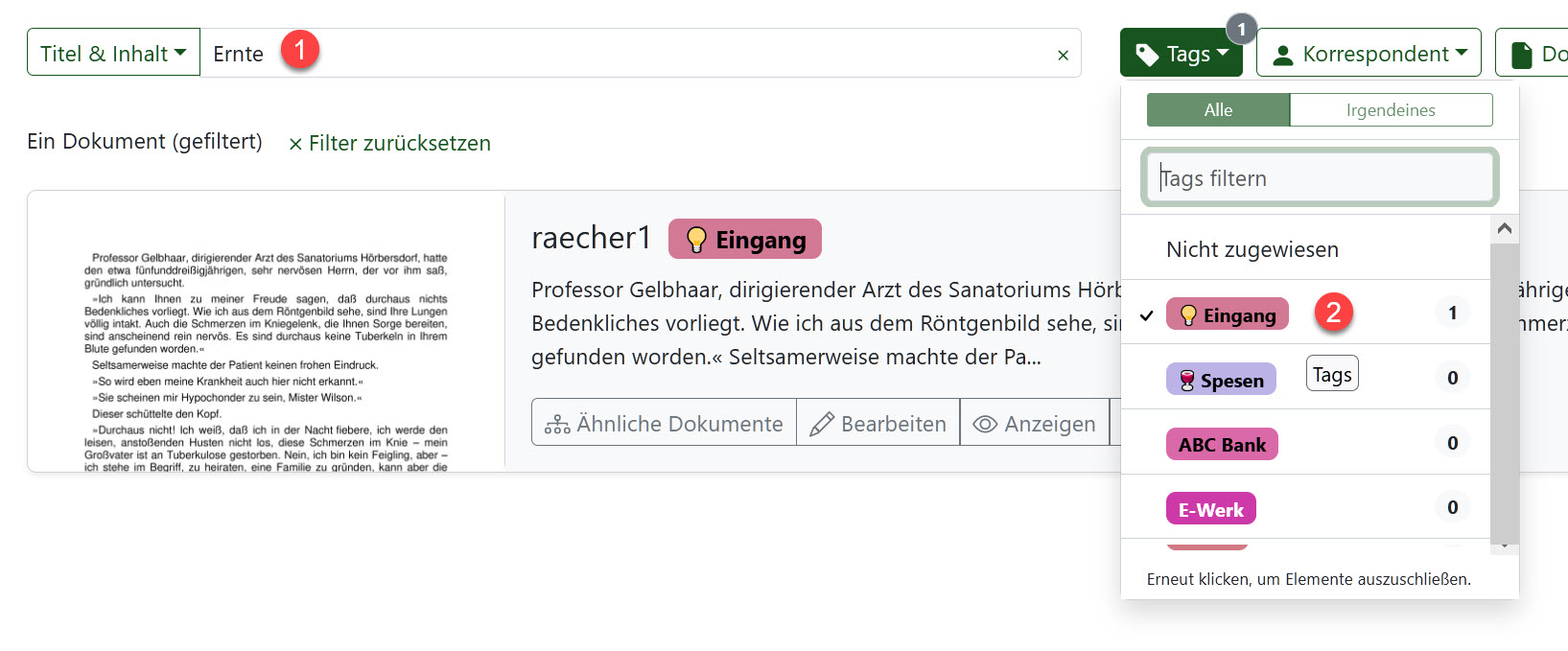
Dabei ist es unwichtig, ob der Tag/die Tags zuerst gewählt oder erst nach erfolgter Suche aktiviert werden.
Erweiterte Suche
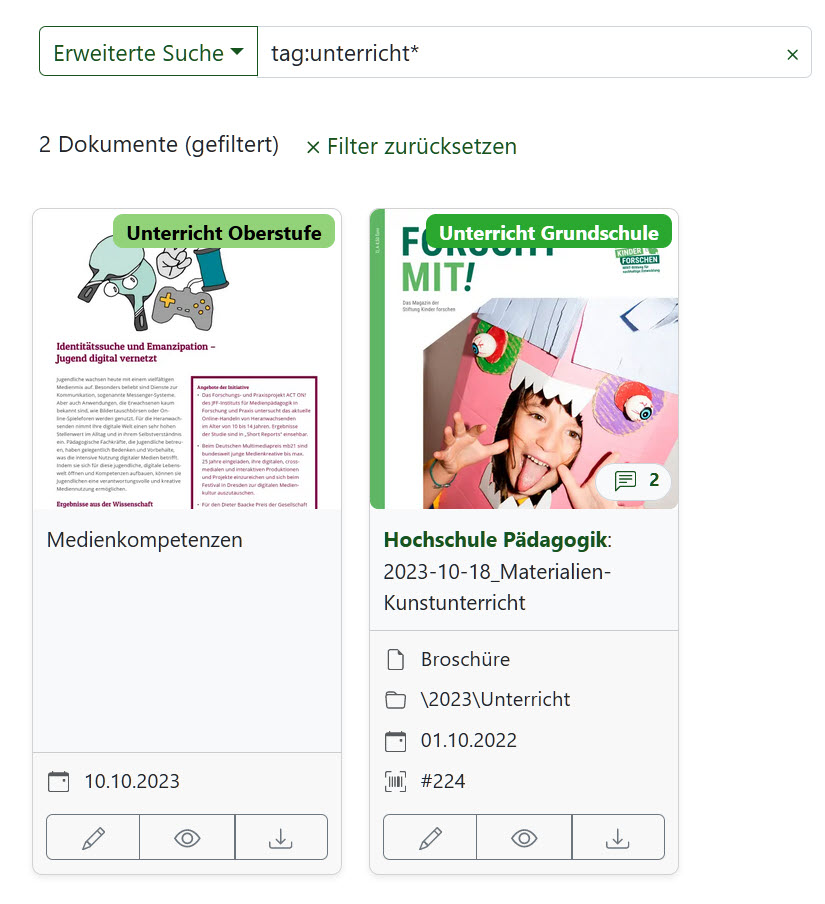
Wer möchte, kann auch komplexere Suchanfragen eingeben und auf den Klick in den Feldern verzichten. Ein einfaches Beispiel wäre der Parameter „tag:“. Wenn ich „tag:unterricht*“ eingebe, so erhalte ich alle Dokumente mit den Tags „Unterricht Oberstufe“, „Unterricht Grundschule“ usw.
Die Parameter kann ich miteinander kombinieren. Beispiel: mit „correspondent:Hochschule“ erhalte ich zunächst alle Dokumente, die die Hochschule betreffen:

Nebenbei: Paperless-ngx stellt den Namen des Korrespondenten vor den Dateinamen, so dass die Ergebnisse klarer ins Auge fallen. Möchte ich aus den Ergebnissen nun nur jene Unterlagen sehen, die ich noch vorbereiten muss, so tippe ich einfach „AND tag:vorbereiten“ dazu:
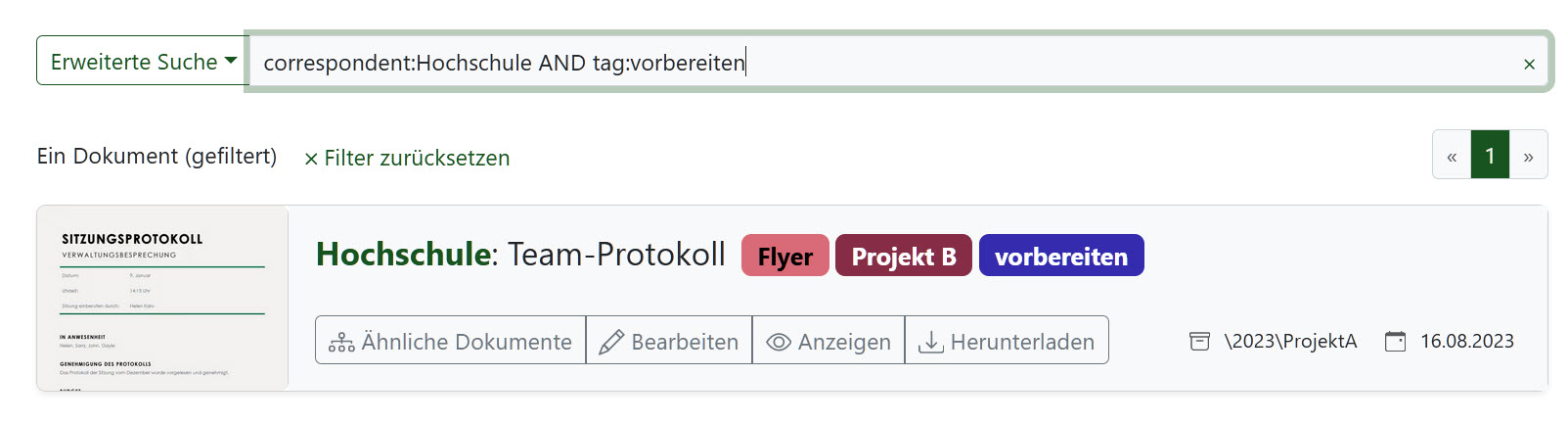
Auch Klammerausdrücke, NOT-Anweisungen usw. lassen sich verwenden. Weitere Hinweise dazu in der Doku des Programms.
Sonderfall: Notizen
Notizen sind keine regulären Felder (der Bereich kann sogar in den Einstellungen gesondert aktiviert/deaktiviert werden). Aber sie können in die Suche aufgenommen werden. Prinzipiell sind Notizen/Anmerkungen zu einem Dokument – z.B. „Ich muss die Tabelle auf S. 12 noch einmal mit den aktuellen Zahlen vergleichen“ – zur späteren Erinnerung ganz nützlich. Man kann darin aber auch beliebige Begriffe eintragen, die bei der Suche auftauchen. Ansonsten bleiben Notizen, bis auf ein kleines Icon, „unsichtbar“.
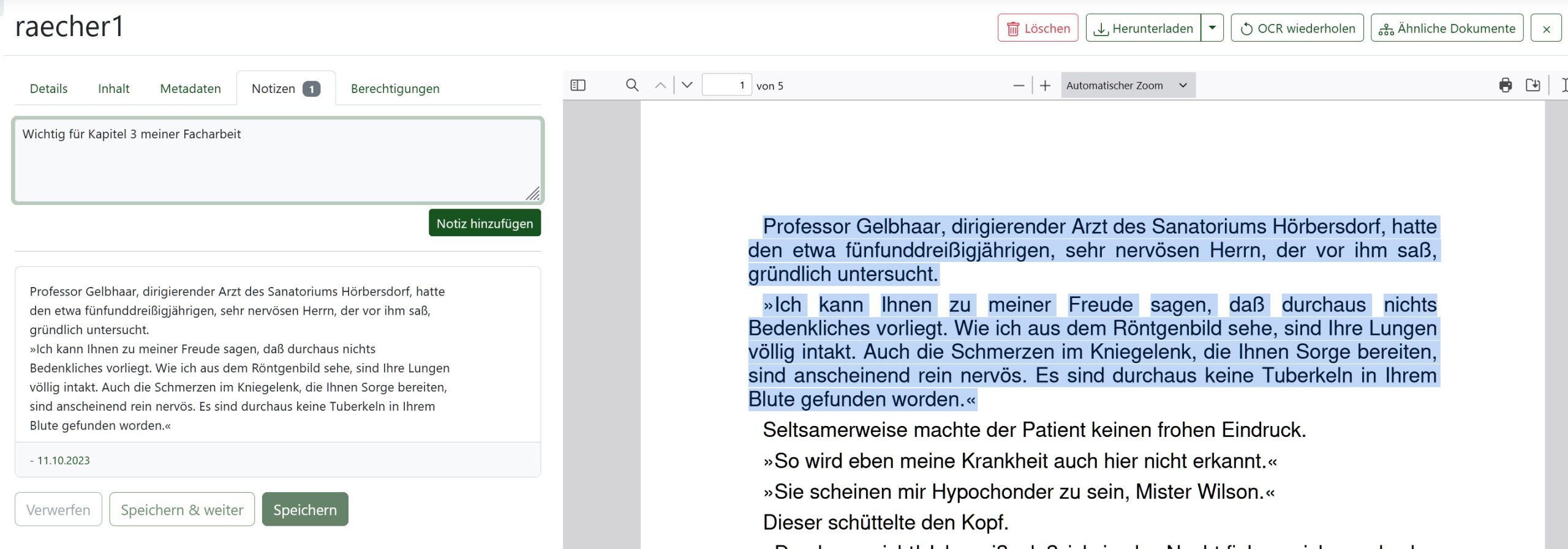
In diesem Beispiel wurde aus dem in Paperless-ngx angezeigten Dokument ein Zitat in eine Notiz kopiert. Zusätzlich wurde eine zweite Notiz zum Dokument erstellt, die auf die Einordnung in einer Facharbeit hinweist. Nach dem Begriff „Facharbeit“ kann nun mit der erweiterten Suche gesucht werden:
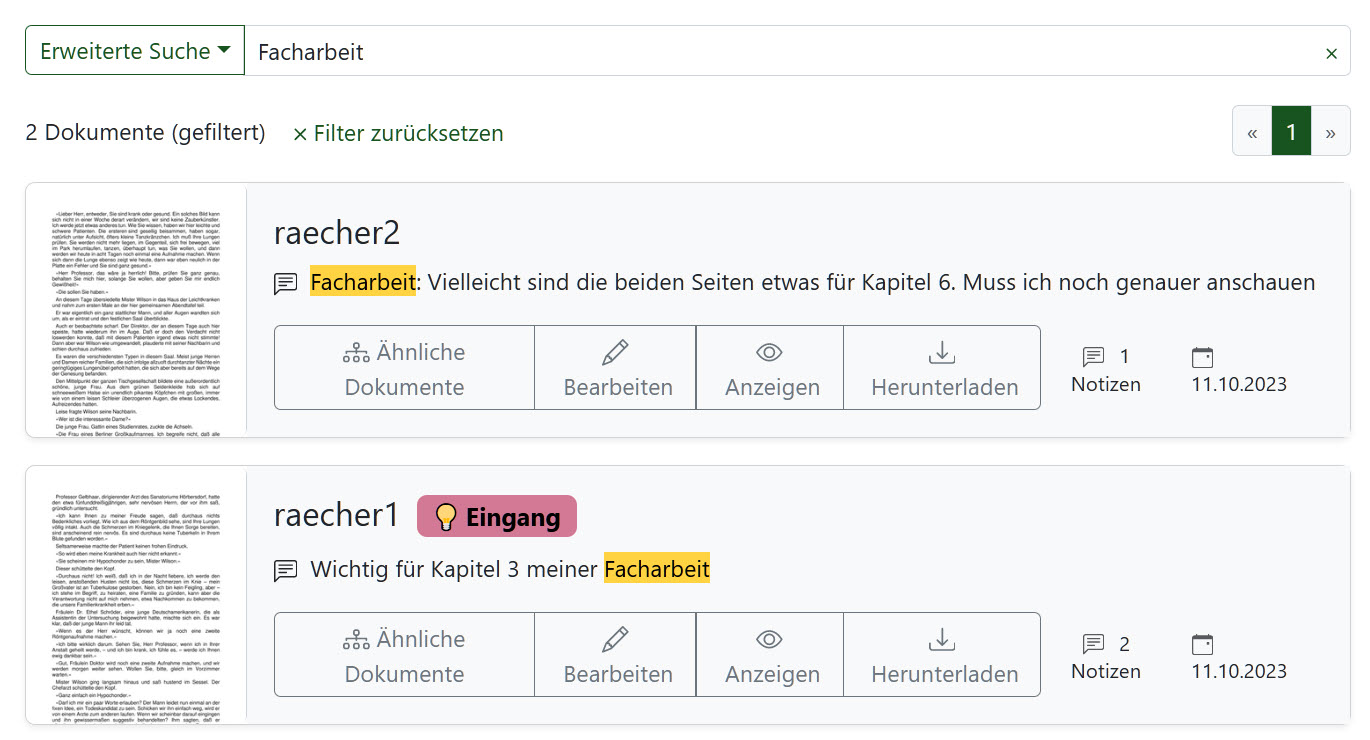
Die Notizen werden gefunden und direkt bei den Suchergebnissen eingeblendet.
Wie bereits in Teil 1 beschrieben: Alle Suchvorgänge lassen sich in Form einer „Ansicht“ speichern und später mit einem Klick abrufen. Die Liste der gespeicherten Ansichten findet sich im Einstellungsbereich, Tab „Gespeicherte Ansichten“.

Die Suche in Paperless-ngx sehr durchdacht. Vor allem: Sie steht nicht nur im Dateimanager eines lokalen Geräts zur Verfügung – alle Geräte im Haushalt/WLAN können darauf zugreifen. Mehr noch: 2 Klicks in einem Router wie der Fritz!Box genügen – und man kann unterwegs via VPN auf alle Dokumente und Suchmöglichkeiten zugreifen. Das Vorgehen beschreibe ich in einem der nächsten Teile.
Was kommt in Teil 3?
Es gibt viele Wege, neue Dokumente in Paperless-ngx aufzunehmen. Die Web-Oberfläche ist ein einfacher Weg. Aber auch Scanner können direkt die Resultate im System speichern, E-Mail-Anhänge können automatisiert in den Index aufgenommen werden, Scanner-Apps auf dem Smartphone arbeiten damit zusammen, ja, sogar iOS-Shortcuts via API sind möglich. Das schauen wir uns alles in Ruhe in der nächsten Folge an …
Bisherige Teile der Paperless-ngx-Serie:
Teil 1: Ausführlicher Überblick
Teil 2: Suche & Tags
Teil 3: consume-Ordner – Einsatz von Scannern
Teil 4: Speicherpfade konfigurieren
Teil 5: Installation auf dem Raspberry Pi
Teil 6: Neue Funktionen in Version 2
Teil 7: Dokumente unterwegs über das eigene Modem abrufen
Teil 8: Exportfunktion nutzen
Teil 9: Update durchführen
Teil 10: Das Rundum-sorglos-Backup
Teil 11: Mail-Abruf mit vielen Extras
Teil 12: Mein Alltag mit Paperless-ngx
Teil 13: Ein Quanten-Code für das Papier-Archiv
Teil 14: Automatisierte Ablage auf Speicherpfaden
Teil 15: Neue Funktion für das Verbinden und Trennen von Dokumenten
Teil 16: Dashboard, smarte Widgets und erweiterte Ansichten
Teil 17: Unterordner des consume-Verzeichnisses nutzen
Teil 18: Paperless-ngx auf Synology/NAS ohne Docker nutzen
Teil 19: Praxisbeispiel – kleine Hausverwaltung
Teil 20: Dokumente per Mail aus dem Heimnetz versenden
Teil 21: Die 1-Klick-Sicherung mit allem Drum und Dran
Teil 22: Update der Datenbank – super-simpel
Teil 23: Neuer PDF-Editor
Teil 24: Der Mega-All-in-One-Befehl für die Sofortinstallation
Teil 25: Der Briefmarken-PC für die Weitergabe
Teil 26: Versionierung und erweiterte Freigabemöglichkeiten


Das könnte dich ebenfalls interessieren

Paperless-ngx, Teil 10: Das Rundum-sorglos-Backup

Frühjahrsputz mit DeClutter (Win)

20 Kommentare
Jörg
Klasse, vielen Dank für diese interessante Serie. Spiele schon länger mit dem Gedanken Paperless-ngx einmal auszuprobieren, ein Synology NAS ist mir aber zu kostenintensiv gewesen. Bisher spielt sich alles papierlos auf meinem Mac ab…was auch sehr gut klappt, aber speziell die vorgestellte Suchfunktion scheint um einiges besser zu sein. Wird die Installation auf dem Raspi noch genauer beschrieben?
Herbert
Ja, für die Raspberry Pi Installation wird es eine Schritt-für-Schritt-Anleitung geben 🙂 Gestern ist die neueste Raspberry Pi OS Version „bookworm“ erschienen, die wollte ich noch abwarten. Auf jeden Fall mal ausprobieren und mit Deiner MacOS-Ablage vergleichen.
Karl-Heinz
Bei einer Neuinstallation von Bookworm beachten:
In der aktuell vom Server gelieferten Version ist ein Fehler beim ersten Update. Die Updateroutine hängt sich auf.
Vor dem Upgrade das realvnc-Paket entfernen, dann upgrade. Dannach kann das Paket wieder installiert werden, oder das realvnc einzeln aktualisieren und dann erst das eigentliche upgrade.
Herbert
Danke für den Hinweis. Meinst Du das Update von Paperless-ngx? Das sollte eigentlich problemlos funktionieren. Oder meinst Du ein Update vom Betriebssystem Raspberry Pi OS?
wobeco
Danke für den Bericht … ich überlege, von Evernote (noch als ß-Tester gestartet) weg zu migrieren.
Nun ist Evernote ja eher Text-orientiert mit der Möglichkeit zu Anhängen jeglichen Formats … hier aber erscheint das Anwendungsszenario eher umgekehrt: Dokumente mit der Möglichkeit für Textergänzungen (i.e. Notizen), oder? Wie könnte da eine Migration von etlichen GB in Evernote nach paperless-ngx realisiert werden?
Und letztlich: was spricht bei vorhandemen NAS (hier: QNAP) dann dennoch für eine getrennte Installation auf einem Raspi?
Herbert
Das sind zwei Unterschiedliche Ansätze. Der Schwerpunkt von Paperless-ngx ist das Dokumentenmanagement – also die Verwaltung von Dateien. Bei Evernote war das kombiniert mit ausführlichen Notizmöglichkeiten, aber dafür war es umständlich, das System zu wechseln. Für mich ist eine sehr gute Kombi: Paperless-ngx für Dokumente plus Obsidian mit seinen ca. 1.000 Plugins für alle Notizangelegenheiten. Und man kann sogar beide Systeme miteinander kombinieren. Und kann jederzeit die Tools wechseln.
Herbert
Noch zu Deiner QNAP-Frage: Wenn ein NAS ohnehin bei Dir läuft, dann muss man keinen Raspberry Pi zusätzlich einsetzen. Meine ältere Synology benutze ich nicht mehr, da inzwischen die Nextcloud alle Aufgaben übernommen hat. Da ist der Raspberry Pi nützlich, denn der verbraucht nur minimal Strom, selbst wenn er 24/7 läuft ca. 10 Euro im Jahr.
Daniel
Vielen Dank für diese Anleitung.
Endlich mal Jemand, der erklären wird, wie das ganze auf dem Raspberry installiert wird.
Ich habe es vor einigen Monaten getan.
Ich hatte große Probleme mit der Freigabe und den Rechten.
Außerdem bekomme ich kein Backup hin.
Ich freue mich drauf
Knut
Besten Dank für diese detaillierte und hilfreiche Anleitung. Hinsichtlich der Suche habe ich eine Frage zu den seit Version 2 möglichen Einrichtung von benutzerdefinierten Feldern. Ich habe ein Feld „steuerrelevant“ mit dem Datentyp „Wahrheitswert“ angelegt. Nach dem Feld kann ich in der Dokumentensuche filtern lassen und erkennen, welche Dokumenten ich dieses Feld zugewiesen habe. Ich möchte aber unterscheiden können nach „nicht abgehakt“ und „abgehakt“ für dieses benutzerdefinierte Feld, um beispielsweise zu erkennen, welche Dokumente noch bearbeitet werden müssen. Gibt es hierfür eine Möglichkeit?
Herbert
Aktuell sind die Werte der benutzerdefinierten Felder noch nicht wirklich durchsuchbar. Wenn man nur das Wort „true“ eingibt, taucht das Gewünschte zwar auf, aber „false“ oder „0“ usw. funktionieren nicht. Eventuell nützliche 2 benutzerdefinierbare Felder mit der Bezeichnung „steuerja“ und „steuernein“ – nicht ganz so elegant, funktioniert aber bei der Suche.
Christoph
Hallo,
in der Version 2.12.1 werden bei mir die Suchbegriffe nicht hervorgehoben. Ist die Funktion weggefallen oder kann man irgendwo einen Haken setzen?
Herbert
Doch, die farbliche Markierung der Suchbegriffe innerhalb des Dokuments ist weiterhin vorhanden. Evtl. hängt es davon ab, ob man in den Optionen eingestellt hat, wie die PDF angezeigt wird (innerhalb des Browsers oder mit einer externen Anwendung).
Christoph
Hallo,
ich habe bei github gefragt. Aber die meinen, es sei kein bug und „Hervorheben“ geht. Evtl. liegt es am Betriebssystem. Ich habe mit win11 chrome, edge und ff probiert. Ohne Erfolg. Aber du nutzt ja auch windows..
In der Android-App funktioniert es…aber ich will ja nicht immer für die Suche zum Tablet greifen. Mal schauen, ob ich noch irgendwo eine Lösung finde.
Christoph
und noch eine Antwort von github:
We don’t make the android app
Advanced search with large cards. Not the hover preview
Mein Englisch ist zu schlecht. Erweiterte Suche mit großen Karten. Nicht die Vorschau.
Aber so funktioniert es. Die Hervorhebung erscheint dann im Text neben dem Dokumentenbild (s. bei dir erstes Bild Kombinierte Suche).
Und tatsächlich nur bei Erweiterte Suche und nur in dem Text.
Nicht in den anderen Suchen, nicht in der Vorschau oder in der Datei, die man im Browser öffen kann. Schade eigentlich.
Früher war mehr Lametta.
Karl
Servus!
Bei mir, V2.13.5, funktioniert das Highlighten der Suchergebnisse leider auch nicht wie in dem Artikel auf dieser Seite beschrieben. Ich habe mich also auf die Suche gemacht und bin auch auf diese Github Seite gestossen mit der sehr knapp gehaltenen Antwort eines Entwicklers. Ich habe versucht, nachzuvollziehen was der Kollege dort mit seiner Antwort gemeint hat und schliesslich herausgefunden wie es geht. Es ist leider nicht zu 100% zufriedenstellend, aber zumindest ein erster Schritt und vielleicht tut sich da ja was in Zukunft.
Hier die Schritte, wie ich es gemacht habe: –
1. Suchbegriff eingeben.
2. Art der Suche auswählen, da gibt es bei mir „Titel“, „Titel & Inhalt“, „ASN“, „Benutzerdefinierte Felder“ und „Erweiterte Suche“: „Erweiterte Suche“ auswählen.
3. Rechts oben gibt es ein paar Buttons: „Auswählen“, „Anzeigen“, Symbole für Liste/Tiles/Voransicht, „Sortieren“, „Ansicht“: Hier auf „Voransicht“ bei den Symbolen klicken.
–> Suchergebnisse werden in einem erweiterten Listenformat mit einer Voransicht angezeigt und hier – und nur hier! – funktioniert das Highlighting.
Wenn man das Symbol für Liste auswählt oder Tiles, dann ändert sich die Anzeige wie gewünscht, aber es gibt leider kein Highlighting.
Letztlich ist es ein Anfang, nicht mehr. Man muss für weitere Suchen halt das entsprechende Dokument extra in einem anderen Programm öffnen und dort weitersuchen.
Vielleicht aber trotzdem hilfreich!
Herbert
Danke für Deine Hinweise! Ich selbst benötige diese Art der Hervorhebung nur sehr selten, da ich meist einfach das Dokument öffne und mit Strg+F und F3 von Suchwort zu Suchwort springen kann.
Sebastian
Hallo erstmal und danke für die vielen Anleitungen.
Ich weiß nicht ob meine Frage hier genau hin passt aber zu Tags u.s.w sollte es passen.
Hat einer von Euch oder Du vielleicht eine Lösung?
Hier meine Frage:
Ich habe einige Dokumente die als Datum nur den Monat und das Jahr haben und dies als Zahl. Beispiel 12.24
Wie bekomme ich es hin, das paperless dies als Datum erkennt und daraus dann z.b. den 01.12.2024 als Datum einträgt. Geht das überhaupt?
Gruß
Sebastian
Herbert
Die Frage ist, ob Paperless-ngx überhaupt ein Datum erkennt – das ist abhängig davon, wie genau dies an welcher Stelle in dem PDF untergebracht ist. Falls es erkannt wird, könnte man einen Arbeitsablauf definieren. Alternativ könnte man auch ein Skript verfassen. Aber das alles lohnt sich nur, wenn es wirklich eine Zeitersparnis bringt. Wenn es nur 5, 6 Dokumente im Monat sind, würde ich es eher per Hand in die Felder eintragen, dann kannst Du auch sicher sein, dass das richtige Datum drin steht.
Andreas
Hallo miteinander,
ich bin seit einiger Zeit auf paperless-ngx und es funktioniert so gut, dass ich auch einen Kollegen angefixt habe.
Beim Lesen dieses Artikels bin ich auf den Hinweis gestoßen, dass bei den Tags die Icons geändert werden können. Allerdings finde ich in Paperless-ngx keine Möglichkeit einem Tag ein Icon zuzuweisen. Kann mir von euch jemand helfen?
Grüße
Herbert
Das geht recht einfach: Alle Betriebssysteme können die üblichen Smileys anzeigen, die man z. B. in WhatsApp verwendet. Unter Windows kann man diese mit „Win-Taste plus Punkt-Satzzeichen“, also „Win + .“ aufrufen. Statt eines Buchstabens klickt man dann ein Symbol aus der Liste an 👍