Paperless-ngx, Teil 3: consume – der (Laub-)Sauger für Dokumente

In Teil 1 wurde die Weboberfläche von Paperless-ngx vorgestellt. Neue Dokumente kann man dort in einem Feld einfach via Drag-and-Drop aufnehmen. Aber es gibt noch einen zweiten Weg, der insbesondere in Verbindung mit Scanner sehr nützlich ist.
Inhalt
Der Ordner „consume“
Auf dem kleinen Home-Server, in dieser Serie ein Raspberry Pi, legt Paperless-ngx zwei Standard-Unterordner an: „export“ und „consume“ (bei mir noch „documents“ – dazu später mehr).

Jede Datei, die in diesem Verzeichnis landet, wird von Paperless-ngx sofort „aufgesaugt“ und ins Archiv übernommen. Anschließend wird die Datei gelöscht. Der Ordner fungiert gewissermaßen als Eingangskorb, in den man die Dokumente legt: Downloads, Materialien, Team-/Projektdateien oder Mail-Anhänge.
Im einfachsten Fall könnte man also einfach die Dokumente auf einen USB-Stick übertragen, diesen in den Raspberry Pi stecken und kurz die Dateien auf den consume-Pfad ziehen:

Doch es geht wesentlich bequemer, da unser Home-Server ja über das WLAN erreichbar ist. Und: „consume“ ist ein ideales Auffang-Körbchen für die Resultate von Desktop-Scannern (oder Smartphone-Apps). Dabei ist es gleichgültig, ob man einen super-teuren Netzwerk-WLAN-Dokumentenscanner oder ein preisgünstiges Drucker-Scanner-USB-Kombiteil verwendet. Lediglich die Vorgehensweise unterscheidet sich ein wenig.

Scan via Raspberry Pi
Der Raspberry Pi erkennt in der Regel problemlos Drucker und Scanner, die im WLAN verfügbar oder am PI via USB angeschlossen sind. Das klappt sogar mit meiner alten HP-Envy-Kombimaschine, die ich vor Jahren mal für 70 Euro beim Media-Markt erstanden habe. Nützlich ist hier das kleine Linux-Tool „Dokument-Scanner“, das im Paket-Manager (mit dem Suchwort „simple_scan“) abrufbar ist. Schlank, verfügt aber über viele Einstellungen.
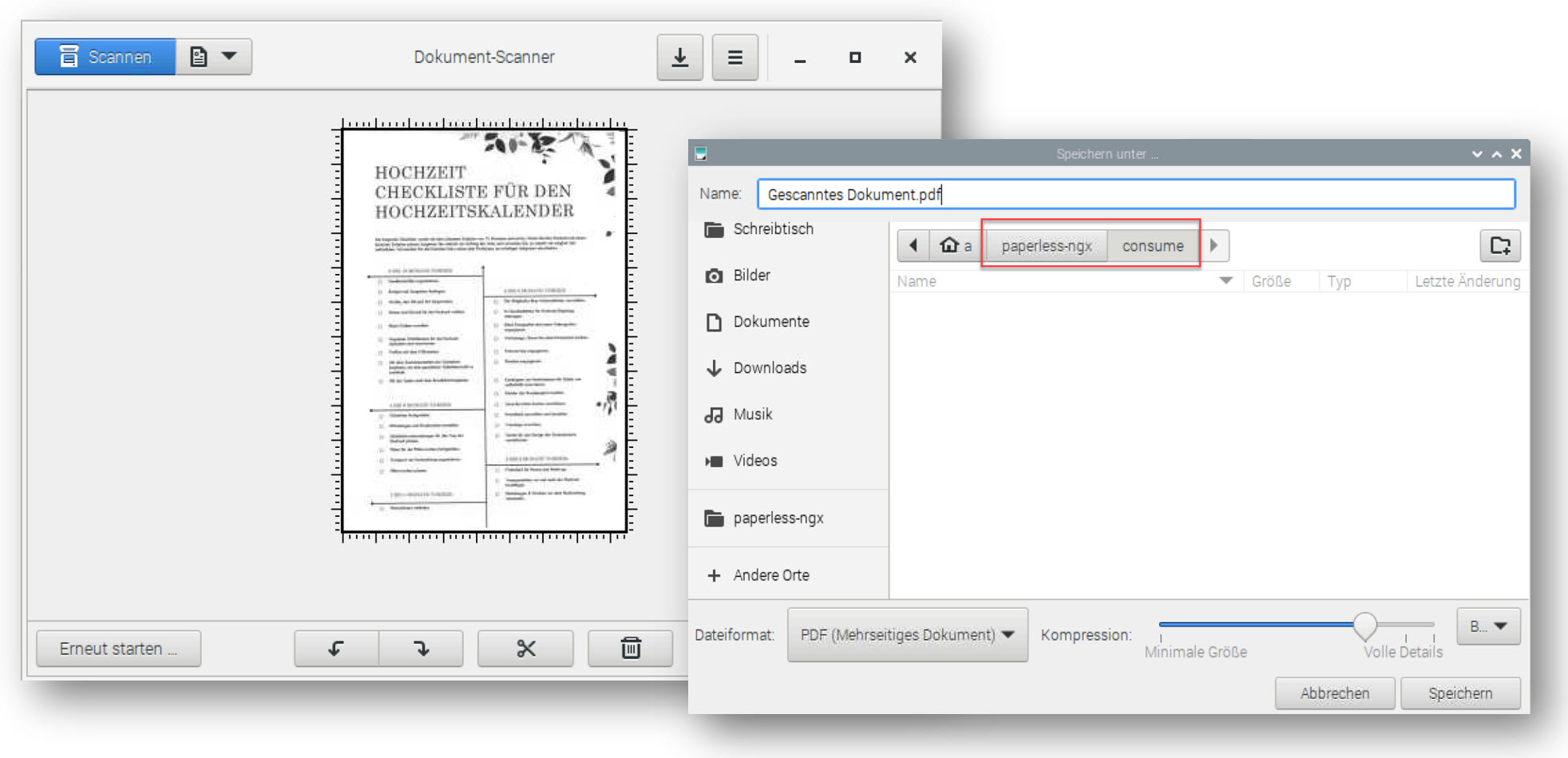
Vorteil: Man muss für die Aufnahme eines neuen Scans nicht den großen Desktop-Computer starten (der Raspberry Pi lässt sich ja auch über ein Smartphone steuern, z.B. via RealVNC). Nachteil: Es ist ein wenig „Gefummel“ und für große Scan-Mengen eher umständlich. Trotzdem: Es klappt – und OCR wird ja von Paperless-ngx erledigt.
Scan via FTP
Scanner mit FTP-Funktion
Auf die Ordnerstruktur des Raspberry Pi kann ja via FTP/SFTP/SSH zugegriffen werden. Wer also über einen (Netzwerk-)Scanner mit entsprechenden Konfigurationsmöglichkeiten verfügt, der hat es sehr einfach. Über die IP, die auch für Paperless-ngx verwendet wird, können die Scans direkt zum Raspberry Pi geschickt werden. Allerdings bieten diese Möglichkeit meist nur Scanner der gehobenen Preisklasse (ab ca. 230,- Euro aufwärts). Dafür erhält man aber auch zusätzlich Duplex-Scan, hohe Verarbeitungsgeschwindigkeiten und zusätzliche Software (z.B. für OCR oder Konvertierungen in verschiedene Dateiformate).
Filezilla und WinSCP
Filezilla kennen viele bereits, da man damit auch auf externe Server zugreifen kann. WinSCP erleichtert Einsteigern etwas den Zugang, da die Oberfläche dem Dateimanager ähnelt.
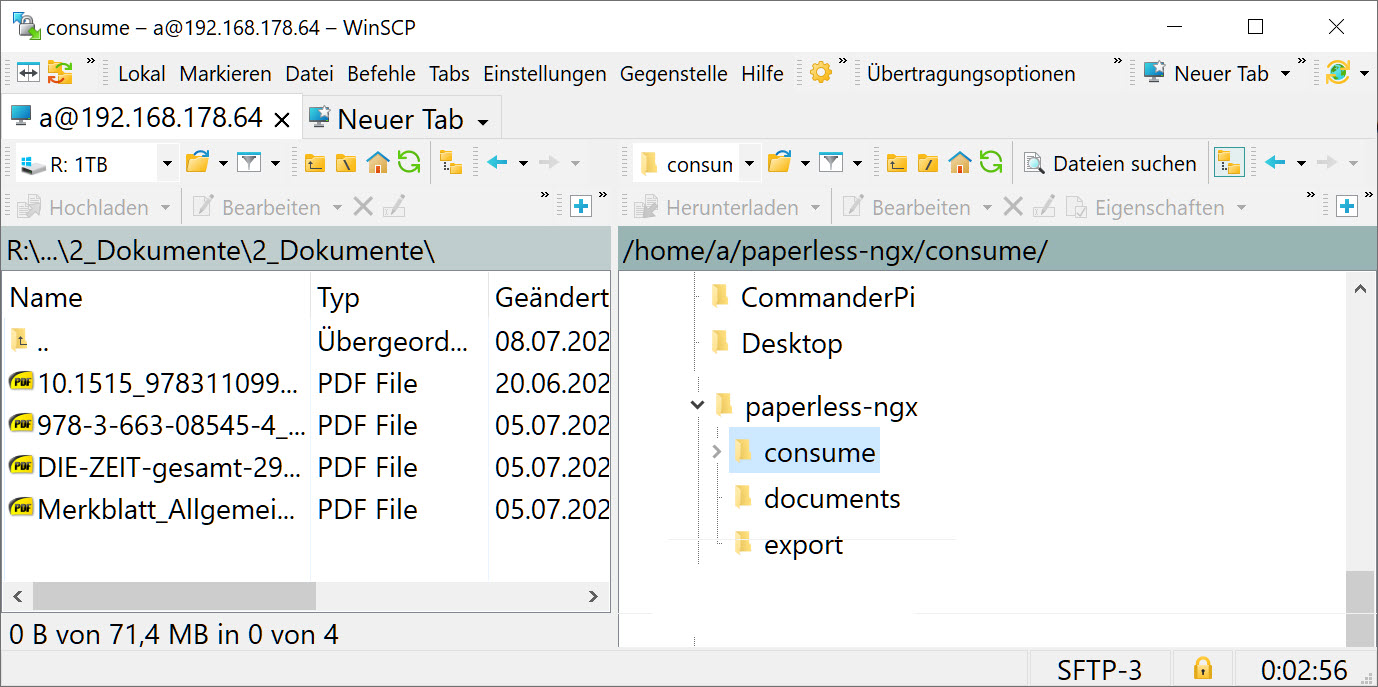
Bei diesen Tools müssen die Dateien „per Hand“ vom Desktop-Ordner in das Raspberry Pi-Verzeichnis gezogen werden. Vorteil: Alle Scanner können in ein Verzeichnis speichern. Oft gibt es Möglichkeiten in den Einstellungen, einen bestimmten Ordner festzulegen. Diesen kann man dann in die Standardeinstellungen seines (FTP-)Tools übernehmen, ohne dass man später immer wieder suchen muss. Also z.B. „C:\meine_scans“ im linken Fenster, „[Raspberry Pi] … consume“ im rechten Fenster.
Überwachte Ordner
Verschiedene Tools können Ordner auf dem Hauptrechner „überwachen“. Wird dort eine neue Datei gespeichert, so landet diese automatisch im consume-Verzeichnis des Raspberry Pi. Zwei bekannte Tools für diese Methode: „Syncthing“ und „FreeFileSync“.
Syncthing
Syncthing ist ein recht verbreitetes Sync-Tool. Dateien werden dabei direkt im heimischen Netzwerk von Gerät zu Gerät übertragen, verschlüsselt und ohne dass jemand eingreifen kann. Ideal, wenn man Dateien z.B. vom Desktop-PC plus Notebook plus Smartphone in den Consume-Ordner aufnehmen lassen möcht.

Die kostenlose Anwendung gibt es für Windows, Mac und Linux. Auch auf dem Raspberry Pi lässt sie sich einfach aktivieren. Für iOS gibt es die Möbius App.
Syncthing verbindet z.B. einen Ordner auf dem DesktopPC mit dem consume-Ordner auf dem Raspberry Pi. Das Tool erkennt, wenn eine neue Datei etwa durch den Scanner in diesem Ordner gespeichert wird. Einige Sekunden später ist die Datei bereits auf den Raspberry Pi übertragen. Da im dortigen consume-Ordner das Dokument nach der Aufnahme durch Paperless-ngx gelöscht wird, verschwindet es auch vom Desktop-PC. Für Vorsichtige: Syncthing hat auch Einstellungen für eine Versionierung von Dateien. Kleine Einarbeitungskurve – aber nach kurzer Zeit hat man den Dreh raus. Ein sehr empfehlenswertes Sync-Tool.
FreeFileSync/RealTimeSync
Auch FreeFileSync (Windows, MacOS, Linux) gehört zu den verbreiteten Tools in diesem Bereich. Durch seine Möglichkeit, Dateien mit FTP/SFTP/SSH zu synchronisieren, ist es ebenfalls für unser Vorhaben geeignet.

Das verbundene Ordner-Paar lässt sich in Form einer Batchdatei speichern und mit dem Zusatztool RealTimeSync ebenfalls überwachen. Das Vorgehen ist ähnelt also der Syncthing-Variante: Der Scanner speichert in einem bestimmten Ordner, die Übertragung auf den Raspberry Pi startet automatisch.
Nextcloud-Sync
Noch einfacher ist es, wenn man ohnehin seine Dateien in einer Nextcloud speichert. Der Desktop-Client ist dann bereits auf den Geräten installiert – und auf dem Raspberry Pi genügt 1 Klick im Paket-Manager – schon hat man ihn auch dort zur Verfügung. Dann nur noch wie bei den vorhergehenden Beispielen bereits beschrieben den consume-Ordner mit dem Scanner-Ordner verbinden – fertig.

Wird nun von einem beliebigen Gerät etwas in den consume-Ordner in der Nextcloud verschoben, so werden die Dateien automatisch auf den Raspberry Pi-Pfad übertragen. Das klappt also auch von unterwegs mit den Nextcloud-Apps auf den mobilen Geräten, ohne dass zu Hause eine Desktop-Computer eingeschaltet ist. Trotzdem ist nach wenigen Sekunden das Paperless-ngx-Archiv ergänzt – und man kann es samt den neuen Dokumenten mobil abrufen.
Ich nutze die Nextcloud sehr intensiv und habe speziell für Paperless-ngx ein getrenntes Nutzerkonto eingerichtet. Dort gibt es nur 3 Pfade: consume, export und documents. Damit verfüge ich jederzeit über ein vollständiges Backup aller meiner Dokumente samt Ordner- und Unterordner. Selbst wenn mein Raspberry Pi zu Hause vom Blitz getroffen würde – könnte mich das kalt lassen …
ScanSnap
Ich habe mir vor vielen Jahren den ScanSnap iX500 geleistet – und er leistet bis heute treue Dienste mit hervorragenden Ergebnissen. Leider hat er keine FTP-Funktion, aber das ist für mich nicht weiter tragisch.

Ich habe mir einen Paperless-Button mit folgenden Einstellungen konfiguriert: OCR, PDF mittlere Größe, erkennen von Datumsangaben, Platzhalter für Datum im Dateinamen, speichern ohne Nachfrage oder Popup-Fenster im Sync-Ordner für Paperless-ngx. Von dort wird die Datei via Nextcloud auf den Raspberry Pi übertragen und eingelesen. Einige Sekunden später kann ich mir das Ergebnis in Paperless ansehen, Tags vergeben, Dateinamen anpassen usw.
Okay, auch Netzwerkordner/Samba/WebDAV kann man nutzen. Aber der Personenkreis, der damit umgeht, benötigt dafür meist keine großen Erklärungen, daher gehe ich hier nicht näher drauf ein.
Aber erwähnen möchte ich noch ein kleines Tool, das im Zusammenhang mit Scannern gute Dienste leiste: NASP2
NAPS2-PDF-Scanner
Preisgünstigen Scannern kommen heute meist ohne besondere Software ins Haus. In diesem Fall hilft das kostenlose Tool „NAPS2“ – Windows, Mac und Linux. Ist schon seit Jahren verfügbar, kann ausgesprochen viel, z.B. auch Profile für verschiedene Scanaufgaben anlegen, Platzhalter für Dateinamen, OCR usw. usw. usw.

Scanner oder Smartphone-App?
Der eigentliche Nachteil an günstigen Flachbettscanner ist die umständliche Handhabung: Deckel auf, Papier rein, Deckel zu, Start der Software usw. Das macht im Alltag keinen Spaß. Eine ganz andere Hausnummer sind Dokumentenscanner: Duplex-Scan, schneller Einzug von vielen Papieren, automatische Ausrichtung, gleichmäßige Beleuchtung, Erkenn-Funktion von doppelten Seiten, OCR-Software, Konfiguration verschiedener Profile usw. usw. Dazu sehr gut lesbare Ergebnisse, die auch „Falt-Unebenheiten“ ausgleichen. Die Anschaffung eines solchen Scanners kann sich für einen papierlosen Arbeitsplatz also durchaus lohnen.
Allerdings muss sagen, dass inzwischen Scan-Apps auf den Smartphones sehr gut geworden sind: Zuschnitt und Ausgleich der Ränder, Kontrast, PDF mit OCR, Platzhalter für Dateinamen. Ein einziger Klick genügt – schon ist der Scan in Paperless-ngx gespeichert. Durch die API von Paperless-ngx kann man unter iOS sogar einen Shortcut definieren, der die Übergabe in einem Rutsch erledigt. Bei geringerem Papieraufkommen können solche Apps bereits ausreichend sein.
In einem der nächsten Teile wird es um den Zugriff auf Paperless-ngx unterwegs gehen. Dann werfen wir auch einen näheren Blick auf die Möglichkeiten solcher Apps, ihre Scans direkt in Paperless-ngx abzulegen.
Was kommt noch?
Es gibt noch eine ganz besondere Möglichkeit der „Befüllung“, die Paperless-ngx beherrscht: Das Tool kann sogar Mail-Anhänge nach einer Vielzahl von Kriterien eigenständig abrufen und in sein Archiv aufnehmen – dazu später mehr.
Eine „Bulletproof Backup Strategy“ habe ich ja schon in Aussicht gestellt. Auf die werde ich auch noch näher eingehen. Und natürlich wird es eine Schritt-für-Schritt-Anleitung zur Installation geben.
Auf Mastodon bin ich unter @_DigitalWriter_@bildung.social zu finden. Unter dem Hashtag „paperlessngx“ poste ich auch gelegentlich kurze Videos zum Umgang mit Paperless-ngx.
Bisherige Teile der Paperless-ngx-Serie:
Teil 1: Ausführlicher Überblick
Teil 2: Suche & Tags
Teil 3: consume-Ordner – Einsatz von Scannern
Teil 4: Speicherpfade konfigurieren
Teil 5: Installation auf dem Raspberry Pi
Teil 6: Neue Funktionen in Version 2
Teil 7: Dokumente unterwegs über das eigene Modem abrufen
Teil 8: Exportfunktion nutzen
Teil 9: Update durchführen
Teil 10: Das Rundum-sorglos-Backup
Teil 11: Mail-Abruf mit vielen Extras
Teil 12: Mein Alltag mit Paperless-ngx
Teil 13: Ein Quanten-Code für das Papier-Archiv
Teil 14: Automatisierte Ablage auf Speicherpfaden
Teil 15: Neue Funktion für das Verbinden und Trennen von Dokumenten
Teil 16: Dashboard, smarte Widgets und erweiterte Ansichten
Teil 17: Unterordner des consume-Verzeichnisses nutzen
Teil 18: Paperless-ngx auf Synology/NAS ohne Docker nutzen
Teil 19: Praxisbeispiel – kleine Hausverwaltung
Teil 20: Dokumente per Mail aus dem Heimnetz versenden
Teil 21: Die 1-Klick-Sicherung mit allem Drum und Dran
Teil 22: Update der Datenbank – super-simpel
Teil 23: Neuer PDF-Editor
Teil 24: Der Mega-All-in-One-Befehl für die Sofortinstallation
Teil 25: Der Briefmarken-PC für die Weitergabe


Das könnte dich ebenfalls interessieren

Digital-Journal: Ihr persönliches Denkarium

Zeiterfassung im Alltag: WorkingHours (alle Systeme)

29 Kommentare
Chris
Ich bin super angefixt und will meine Datenmengen unbedingt in paperless aufbehmen. Ein ungenutzter Raspi 4 liegt hier rum und wartet.
Gibt es einen Zeitplan, wann etwa die Installationsanleitung kommen wird? Bin schon ganz hibbelig.
Gruß
Chris
Herbert
Ich wollte noch warten, bis ich das neue Raspberry Pi 5 Modell erhalten habe – sollte aber in den nächsten Tagen bei mir sein. Falls es sich verzögert, schreibe ich die Install-Anleitung entlang vom Raspberry Pi 4.
Verena
Vielen Dank für die tollen Beiträge. Ich betreibe paperless-ngx auch auf einem Raspi 4.
Manchmal „vergisst“ Paperless ein Dokument im consume folder. Gibt es eine Möglichkeit, den Prozess noch einmal manuell anzustoßen? Erst wenn ich einen kompletten Restart mache, wird das Dokument verarbeitet…
Herbert
Ich schau mal, ob ich dazu etwas finde. Prinzipiell ist es nicht tragisch, wenn etwas im consume-Ordner verbleibt und erst nach einen Neustart verschwindet. Eine Ursache könnte der Weg sein: Wie „landet“ denn das Dokument im consume-Pfad? Via Web-Frontend?
Verena
Danke. Das Dokument wird direkt als pdf vom Dokumenten-Scanner in dem Ordner gespeichert.
Florian
Ich könnte mir vorstellen, dass dein Scanner in der Datei noch schreibt und paperless-ngx diese deshalb nicht lesen kann. Mein Scanner arbeitet so, da er nachfragt ob noch eine weitere Seite gescannt werden soll. Ich denke hier hilft ein Zwischenschritt mit Ablage in ein Scan Verzeichnis dass von einem Tool in das consume Verzeichnis synchronisiert.
Sebastian
Auf dem Raspberry Pi 5 findet man das Tool „simple_scan“ unter diesem Namen nicht. Unter „simple-scan“ hingegen schon.
Bernd
Hallo Herbert,
vielen Dank für deinen tollen Blog!
Die Installation hat wunderbar geklappt und ich denke soweit läuft alles.
Die ersten Dokumente habe ich per Drag and Drop eingelesen 🙂
Nun habe ich das consume Verzeichnis auf mein IN Verzeichnis auf dem NAS gemountet.
Wenn ich Dateien dort rein lege, sehe ich diese im Verzeichnis, von papaerless werden diese aber nicht beachtet.
Was mache ich falsch?
Vielen Dank!
Bernd
Herbert
Da ich nicht weiß, welches NAS du verwendest, kann ich jetzt nur für Raspberry Pi/Linux sprechen: dort benötigt auf der Systemebene Paperless-ngx ein „Ping“ als Info über neue Dateien. Das liefert nicht jeder Übertragungsweg (z.B. FTP nicht). Du kannst dann alternativ ein Polling-Intervall einstellen, damit sollte es klappen. Einzelheiten dazu sind hier zu finden: https://docs.paperless-ngx.com/configuration/#polling
Bernd
Danke für die Antwort!
Nachdem ich verstanden habe, dass Änderungen in der docker-compose.env durch den Befehl „docker-compose up -d“ aktiv werden funktioniert es mittels polling.
Kleine Hürden, die ich zwischendrin genommen habe:
Wo trage ich die Konfigutrationen ein?
Beides ist möglich docker-compose.env und docker-compose.yml. – Allerdings wird in der .env der Wert zur Variable mit „=“ getrennt und in der .yml mit „:“. Steht natürlich auch in der Dokumentation 😉
Daniel
Hallo, tolle ausführliche Anleitung!
Ich hatte früher Probleme mit der Samba Freigabe des Consume Ordners.
Syncthing habe ich jetzt am Laufen.
Ich hätte allerdings doch lieber einen Ordner auf dem Raspberry 5, da der ja 24/7 läuft.
Gibt es noch eine Möglichkeit einen Ordner im Netzwerk freizugeben ohne Samba?
Wie Du schon richtig schreibst, Samba und Windows kann kompliziert werden.
Daniel
Ich möchte noch ergänzen…
Ich habe einen brother ADS-1700W Netzwerkscanner.
Damit möchte ich in den Consume Ordner auf dem Raspberry scannen.
Herbert
Hallo Daniel,
das sollte gar kein Problem sein. Du möchtest von Deinem Brother-Scanner direkt auf den Raspberry Pi ins consume-Verzeichnis scannen, ohne zusätzlich den Desktop-PC anschalten zu müssen? Wenn ich das Datenblatt Deines Scanners richtig lese, so kann er Samba, SFTP/FTP und Mail – mit allen Möglichkeiten kannst auf den Raspberry Pi zugreifen, indem Du das consume-Verzeichnis dort zur Verfügung stellst. Samba auf Linux funktioniert – im Unterschied zu Windows – recht gut. SFTP wäre meine persönliche Wahl, da man SSH ohnehin meist für den Raspberry Pi freigegeben hat. NTFS wäre noch eine Möglichkeit. Zuletzt könnte man noch an eine Mail-Adresse die Scans senden, die Paperless-ngx abruft – aber das erscheint mir zu umständlich. Sofern Du MX Linux auf dem Raspberry Pi laufen hast, kannst Du dort die Samba-Einstellungen aufrufen und mal ausprobieren. Wenn Du Raspberry Pi OS verwendest, dann würde ich es mit SFTP probieren.
Oliver
Hallo Herbert,
seit 2-3 Jahren läuft ein paperless-ngx auf einem virtuellen Debian was auf meinem kleinen Proxmox mitläuft.
Ich scanne noch viel zu wenig und nicht regelmässig.
Durch Zufall bin ich in den letzten Wochen über Deine Seite gestolpert und habe mir vorgenommen einige Deiner Tipps als neuen Ansporn und Workflow Anregung zu nutzen. 🙂
Ich habe einen Brother ADS1700WUN1 mit dem ich Dokumente direkt über wlan zu paperless schicke.
Leider zieht der gerne mal schräg ein. 🙁
Nun habe einen Fujitsu fi-7100 abstauben können und bin am überlegen, wie ich desen Scans auch direkt zu paperless schieben kann. Der muss über USB angeschlossen werden. Am liebsten wäre mir ja, da einen kleinen Pi dran zu hängen, der eine feste Einstellung hat und Scans dann automatisch zu paperless schiebt.
Kannst Du da was empfehlen, was man da am besten nutzt oder wäre da evtl. auch NAPS2 (habe ich mir noch nicht angeschaut) das Tool der Wahl?
Grüße,
Oliver
Herbert
An welchem Gerät wird denn der USB-Scanner angeschlossen? An dasjenige, auf dem auch Paperless-ngx läuft? Dann könnte man mit NAPS2 schauen, dass der Scan im consume-Ordner gespeichert wird. Alternativ kannst du mal nach Bastelanleitungen für einen Raspberry Pi suchen. Man sollte damit aus älteren Geräten einen Netzwerk-Scanner fabrizieren können – habe ich aber noch nicht probiert.
T
Ich mache es mir einfacher indem ich in der docker-compose den consume ordner als „gescannt“ auf mein Netzlaufwerk lege und dies auch der Zielordner für jegliche Dokumente (zb one klick scan des Netzwerkscanners) ist. Zu beachten dass auf „nicht windows smb“ wegen fehlendem inotify der consume ordner mit PAPERLESS_CONSUMER_POLLING=10 über die .env abgefragt werden sollte.
testmatz01
Erstmal vielen Dank fūr die sehr interessante Einfūhrung zu paperless.
Ich hab eine Frage zur Installation. Im Bild oben sind die Ordner consume, documents und export im Ordner paperless-ngx zu sehen. Meine Frage dazu: muss man diese Ordner bei einer Docker-Installation außerhalb des Dockers manuell anlegen, oder macht dieses das skript automatisch?
Danke im Voraus.
Testmatz01
Herbert
Man muss während der Installation angeben, auf welchem Pfad diese Ordner gespeichert werden sollen. Die Einzelheiten dazu habe ich in Teil 5 im Abschnitt „Die Abfragen“ (Media folder) beschrieben. Wenn die Installation bereits erfolgt ist, so kann man die Pfad-Angabe auch in der yml-Datei nachträglich anpassen.
Dominik
Sollte der Scanner auf dem Raspberry Pi oder dem Windows-Desktop-PC installiert werden?
Herbert
Wenn Dein Scanner direkt zum Raspberry Pi übertragen kann, so musst Du nichts installieren. Es genügt, wenn Du direkt am Scanner die IP im Heimnetzwerk einstellst.
Stephan
Vielen Dank für die tolle Serie zu Paperless NGX,
du hast mich inspiriert meine Post auf nahezu papierlos umzustellen. Paperless NGX läuft dank Deiner Anleitung sauber in Docker auf einem Raspi. Vor kurzem habe ich mir ein EPSON ES-580W zugelegt um einen ganzen Schwung alter Ordner nach Papaerless zu schieben und dann zu entsorgen. Der Scanner ist Netzwerkfähig und kann FTP und SFPT … nur ich kann es scheinbar leider nicht 😉
Muss dazu noch die yml file angepasst werden ? oder hast Du sonst noch einem Tipp damit ich das Consume Verzeichnis direkt vom Scanner aus befüllen kann.
Bin für jede Hilfe oder Idee dankbar
vG
Stephan
Herbert
Wichtig ist die Freigabe des Consume-Ordners. Kannst Du mit einem SFTP-Programm wie Filezilla darauf zugreifen und Dateien speichern? Evtl. musst Du noch den Scanner als Nutzer eintragen – das unterscheidet sich von Betriebssystem zu System. Da ich keinen Epson habe, weiß ich leider nicht, was man da alles eintragen kann. Hast Du denn einen Raspberry Pi und nimmt das aktuelle 64-Bit-OS von Raspberry Pi?
Stephan
Hallo Herbert,
vielen Dank für die schnelle Rückmeldung. Mit Filezilla funktioniert das ohne Probleme. Da habe ich zum testen Dokumente, via SFTP, in de consume Ordner mit Unterordner geschoben um auch das taggen zu testen. Alles bestens. Meine Paperless NGX Instanz läuft in einem Docker Container auf einem Raspi mit dem aktuellen OS. Auch ohne Probleme, dank Deiner Anleitung 😉
Dann sollte es ja auch mit dem Epson funktionieren. Ich werde mich mal langsam rantasten.
Vielen Dank für die tolle Reihe und ich freue mich auf das nächste Kapitel
vG
Stephan
Carmen
Hallo,
danke für deine Anleitungen. Damit habe ich alles problemlos auf einem Raspi zum testen installieren können. Bin totaler Noob was Linus betrifft.
Allerdings habe ich das Problem, dass Dateien aus dem consume-Ordner nicht automatisch installiert werden. Habe alles so angegeben, wie in Deiner Anleitung. Hast Du vielleicht ne Idee, woran das liegen könnte? Danke
VG Carmen
Herbert
Auf welchem Weg speicherst Du die Dateien auf dem Pfad? Probier‘ mal: 1. PDF in ein anderes Verzeichnis auf dem Raspberry Pi speichern. 2. Von dort nach consume kopieren. Wird dann die Datei erkannt und anschließend gelöscht?
Ralf
Hallo, können Sie mir bitte helfen, mein brother ADS 1800W über USB mit dem Raspberry pi 4 zu verbinden, mit Paperless ngx , seit 3 Tagen bin ich schon dran bekomme es irgendwie nicht hin. Gruß Ralf
Herbert
Eigentlich sollte mit einem aktuellen Raspberry Pi OS ein USB-Drucker erkannt werden. Falls nicht: CUPS installieren. Das Vorgehen wird hier beschrieben: https://www.elektronik-kompendium.de/sites/raspberry-pi/2007081.htm
Schreibfehlerfinder
Ich durchsuche das Netz nach Schreib- und Tippfehlern. Hier habe ich einen gefunden: „Das Toll erkennt“.
PS: Danke für die tolle Anleitung!
Herbert
Danke für den Hinweis!