Paperless-ngx, Teil 4: Speicherpfade konfigurieren

Das Problem von guten Tools: Man gewöhnt sich an sie, man richtet seinen ganzen Workflow entsprechend aus, freut sich des Lebens – und eines Tages? Plopp! Weg ist das Tool. Die Entwickler sind entschwunden. Nach einem Update funktioniert nichts mehr. Man hat das System gewechselt oder ein besseres Tool gefunden usw. usw. In einem Satz: Der bisherige Workflow funktioniert nicht mehr, es muss neu begonnen oder konvertiert werden, viel Zeit und Mühe muss für die Rettung des eigenen Systems aufgebracht werden. Die gute Nachricht: Das muss nicht sein. Wenn man auf wenige Punkte bei Paperless-ngx achtet, so muss man sich um die Zukunft keine Gedanken machen.
Inhalt
Der Ausgangspunkt: Dateien, Namen und Ordner
In „Digital Cleaning“ habe ich ein System ausführlich beschrieben, das viele von Euch in unterschiedlichen Varianten für ihre Dateien ohnehin einsetzen werden: Ausgangspunkt sind einige Ordner mit möglichst wenig Unterordnern. Darin Dokumente, deren Dateinamen einem Muster folgen. Etwa „Kapitel_01-1.pdf“, „Kapitel_02-1.pdf“ oder „2023-11-01_Rechnung-Schornsteinfeger.pdf“ usw. Nehmen wir an, das Ergebnis sieht im Dateimanager etwa so aus:
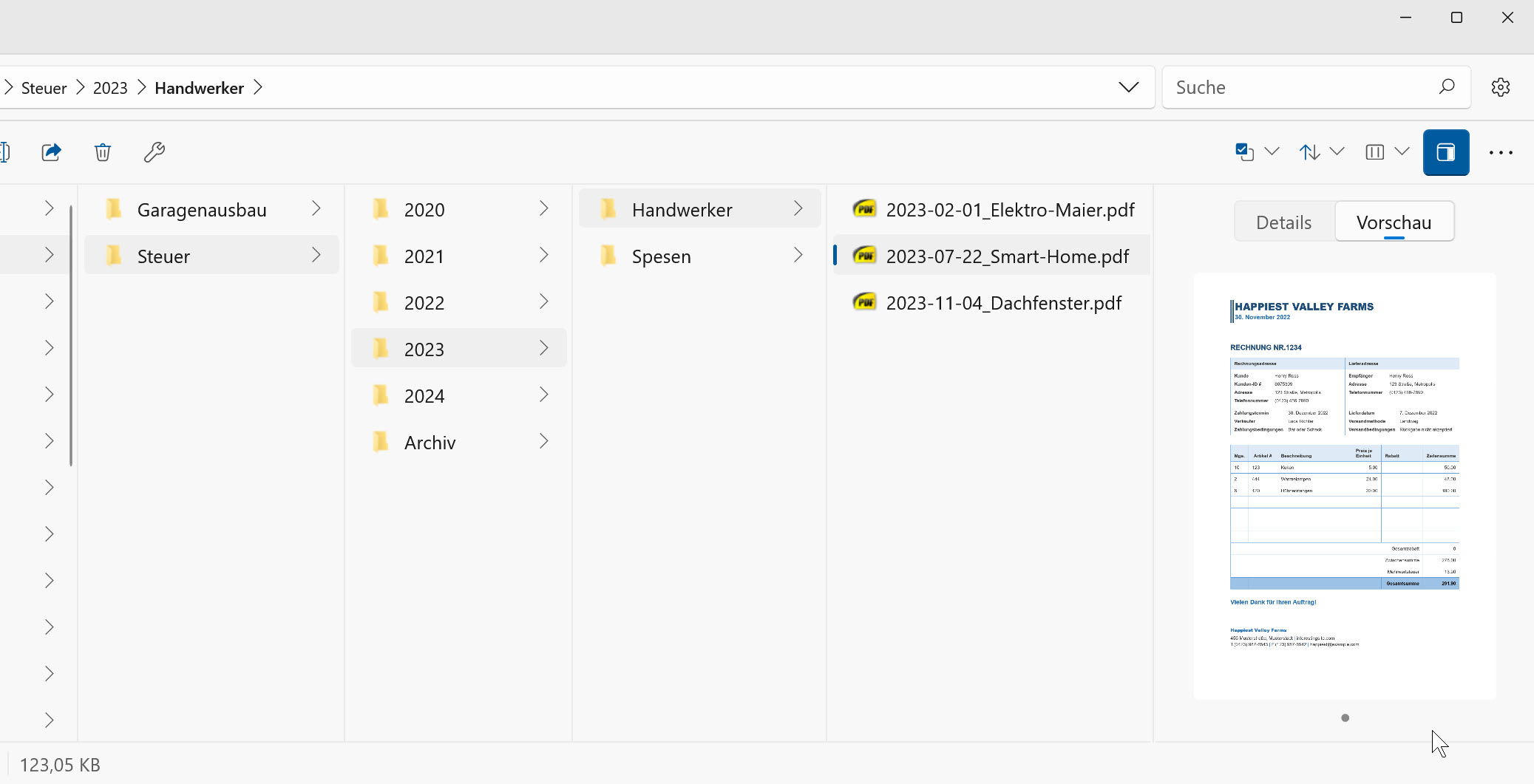
Je nach Dateimanager ist das Erscheinungsbild etwas anders, aber immer wird eine Struktur erzeugt, die es erleichtert, große Dokumentenarchive einzugrenzen und den Überblick zu bewahren:
Mit solchen Mustern kommt man sehr weit, sie funktionieren unter jedem Betriebssystem – und man benötigt kein zusätzliches Tool. Mit der Suchfunktion wird man in einer akzeptablen Zeit meist fündig. Paperless-ngx kann nun die aufgenommenen Dokumente in der gleichen Weise ablegen und in Form eines „normalen“ Verzeichnisbaumes zur Verfügung stellen. Falls also irgendwann einmal um 13:02 Uhr an einem Sonntag Paperless-ngx aus diesem Universum verschwindet – so habe ich um 13:03 alle meine Dateien mit den gewählten Bezeichnungen und mit der von mir angelegten Ordnerstruktur auf meinen Speichermedien, ohne dass etwas exportiert oder konvertiert werden müsste. Gut, auf die in den vorherigen Teilen beschriebenen „Bonbons“ von Paperless-ngx – also etwa die Tags – muss man verzichten oder sich ein neues Tool suchen. Aber das sollte in den meisten Fällen verschmerzbar sein.
Ordner in Paperless-ngx einrichten
Hinweis: In den Beispielen sind die Platzhalter mit jeweils einer geschweiften Klammer aufgeführt (z. B. „{ title }“. Inzwischen bevorzugt Paperless-ngx zwei geschweifte Klammern („{{ title }}“).
Ohne besondere Vorkehrungen versieht Paperless-ngx die Dateinamen einfach mit fortlaufenden Nummern, was natürlich nicht in unserem Sinn ist.

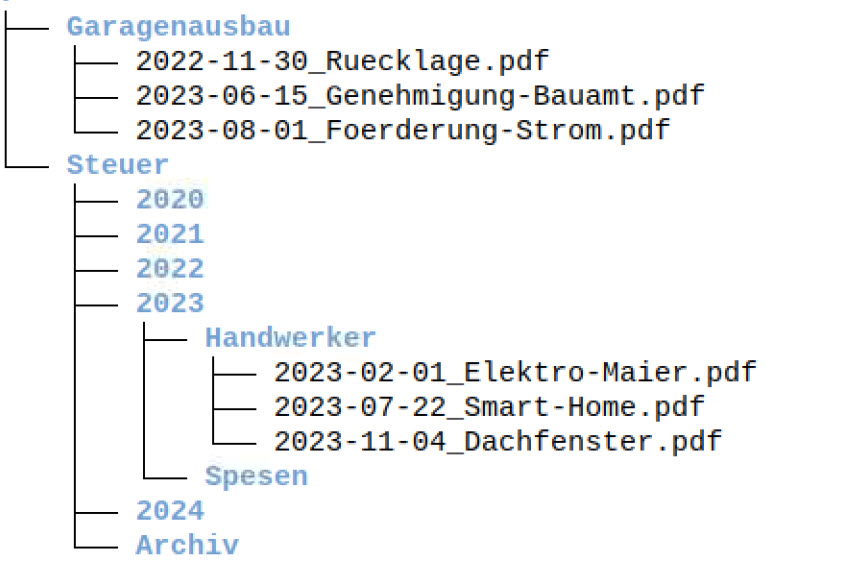
Die Anwendung muss a) die Anweisung erhalten, unsere eigenen Dateinamen zu verwenden und b) Unterordner anzulegen. Dazu wird das Feld „Speicherpfad“ benutzt:

Durch den Platzhalter „{title}“ wird der gewählte Dateinamen beibehalten. Paperless-ngx stellt sehr viele derartiger Platzhalter zur Verfügung (siehe Liste), so dass man die Vergabe eines Speicherpfads auch automatisieren könnte. Wenn Paperless-ngx beispielsweise ein bestimmtes Entstehungsdatum einem Schreiben entnehmen kann, so könnte das Dokument automatisiert in den entsprechenden Jahres-Unterordner abgelegt werden. Ich persönlich bin etwas vorsichtiger und verwende Platzhalter sparsam. In obigem Beispiel lautet die Pfad-Anweisung „{owner_username}/Steuer/2023/Handwerker/{title}“. Mit {owner_username} wird der Account-Inhaber eingesetzt – bei meinen Beispieldokumenten handelt es sich um den virtuellen „Mika“. Danach Ordner, Jahr und Unterordner im Klartext („Steuer/2023/Handwerker“). Abschließend folgt „{title}“ für den Dateinamen.
Damit entsteht im Ordner „archive“ folgende Struktur:

Komplexe Platzhalter
Platzhalter wie {title} oder {created_year} gehören zu den einfachen Komponenten. Es lassen sich aber auch deutlich komplexere Angaben abbilden. Wenn man es beispielsweise bei seinem Studium mit der Hochschulverwaltung, der Studentenvertretung und dem Gutachter der Examensarbeit zu tun hat, so könnte man drei „Korrespondenten“ eintragen: „Verwaltung“, „StuVe“ und „Maier-Luedenscheidt“. Dann könnten die Platzhalter wie folgt eingetragen werden:
„Hochschule/{correspondent}/{created_year}-{created_month}-{created_day}_{title}“
Das Ergebnis wäre: „Hochschule/Verwaltung/2023-11-01_Studiengebuehren.pdf“ oder „Hochschule/Maier-Luedenscheidt/2023-07-15_Gliederungsvorschlag.pdf“ (sofern man Einträge im Feld „Korrespondent“ vorgenommen hatte).
Sprechende Namen
Die Überschrift (der Name) für die Speicherorte kann frei gewählt werden, sie muss also nicht deckungsgleich mit der Pfadbezeichnung sein. Statt also einen umständlichen Namen wie „Mika/Steuer/2023/Handwerker“ einzutragen, kann auch eine Kurzform wie „Rechnungen“ oder „Spesen“ genommen werden (in obigem Beispiel wurde „Steuer – Handwerker“ gewählt). Bei einer größeren Anzahl von Speicherorten findet man in der Liste so rascher den korrekten Pfad.
Flexibilität
Möchte man nach einiger Zeit „umsortieren“, so ist das mit dem erwähnten Verfahren besonders elegant: Man passt einfach die bisherige Pfadangabe an – in der gleichen Sekunde sind alle Dokumente mit diesem Speicherort verschoben. Vielleicht möchte ich statt zwei Ordnern „Steuer/2023/..“ nur noch einen verwenden, der sich „2023_Steuer/..“ nennt – kein Problem. Der Pfad wird nur 1 x in der Liste der Speicherordner geändert – sofort liegen alle bisherigen Dokumente im Ordner „2023_Steuer“ und die alten Ordner sind im gleichen Zug verschwunden.
Man wird rasch merken, dass dieses Verfahren im Alltag deutlich bequemer im Vergleich zum bisherigen Vorgehen ist: Dateimanager öffnen, alten Pfad ansteuern, alle Dateien markieren, Kopierbefehl, neuen Ordner anlegen, Dateien einsetzen, alten Pfad löschen. Jetzt ist es nur noch ein Klick – erledigt.
Ersteinrichtung leicht gemacht
Schön wäre es, wenn man eine bestehende Ordnerstruktur einfach in Paperless-ngx aufnehmen könnte. Also nicht nur die Dateien importieren könnte, sondern auch Ordner und Unterordner. Das geht leider aktuell (noch) nicht. Aber der Zeitaufwand bei der Ersteinrichtung hält sich sehr in Grenzen, da man keineswegs jede Datei einzeln einem Speicherort zuordnen muss. Man kann dies „in einem Rutsch“ erledigen. Die Dateien werden markiert, das Speicherpfad-Menü aufgeklappt – und schon sind alle Dokumente am vorgesehenen Ort gespeichert:

Mein eigenes Beispiel: Ich habe in den letzten 6 Jahren rund 1.000 Dateien in einem Verzeichnisarchiv auf meiner SSD gespeichert. Durch die Namensmuster konnte ich die Verschachtelung mit Unterordnern klein halten: Es gibt 4 Hauptordner mit übergreifenden Themen („Hausangelegenheiten“, „Alte Dokumente bis 2018“ usw.). Darin höchstens 2 Unterordner – also insgesamt etwa 10 Verzeichnisse.
Bei der Übernahme schiebe ich nun immer 1 Verzeichnisbündel auf den Pfad „consume“. Dann eine Weile warten, bis der Index in die Datenbank aufgenommen wurde. Anschließend die neuen Dateien markieren – und den zugehörigen Speicherpfad zuweisen. Am Ende habe ich eine 1:1-Kopie meiner bisherigen Ordnung in Paperless-ngx. Erleichtert wird die Auswahl durch den Speicherpfad-Menüpunkt „Nicht zugewiesen“:

Damit werden alle Dokumente ausgeblendet, denen bereits ein Speicherort zugewiesen wurde (alternativ könnte man auch den Eingangs-Tag nehmen und diesen nach der Vergabe löschen).
Ohnehin besteht der eigentliche Zeitaufwand bei der Übernahme eines großen Datenbestandes in der Erst-Indizierung des Dokumenteninhalts. Die 10 Klicks für die Zuweisung von Speicherorten fallen da kaum ins Gewicht.
Bisherige Teile der Paperless-ngx-Serie:
Teil 1: Ausführlicher Überblick
Teil 2: Suche & Tags
Teil 3: consume-Ordner – Einsatz von Scannern
Teil 4: Speicherpfade konfigurieren
Teil 5: Installation auf dem Raspberry Pi
Teil 6: Neue Funktionen in Version 2
Teil 7: Dokumente unterwegs über das eigene Modem abrufen
Teil 8: Exportfunktion nutzen
Teil 9: Update durchführen
Teil 10: Das Rundum-sorglos-Backup
Teil 11: Mail-Abruf mit vielen Extras
Teil 12: Mein Alltag mit Paperless-ngx
Teil 13: Ein Quanten-Code für das Papier-Archiv
Teil 14: Automatisierte Ablage auf Speicherpfaden
Teil 15: Neue Funktion für das Verbinden und Trennen von Dokumenten
Teil 16: Dashboard, smarte Widgets und erweiterte Ansichten
Teil 17: Unterordner des consume-Verzeichnisses nutzen
Teil 18: Paperless-ngx auf Synology/NAS ohne Docker nutzen
Teil 19: Praxisbeispiel – kleine Hausverwaltung
Teil 20: Dokumente per Mail aus dem Heimnetz versenden
Teil 21: Die 1-Klick-Sicherung mit allem Drum und Dran
Teil 22: Update der Datenbank – super-simpel
Teil 23: Neuer PDF-Editor
Teil 24: Der Mega-All-in-One-Befehl für die Sofortinstallation
Teil 25: Der Briefmarken-PC für die Weitergabe




32 Kommentare
Hans-Helge
Das Paperless die Dateien automatisch umbenennt und in meine vordefinierte Ordner-Struktur ablegt, war damals ein Hauptgrund, warum ich das System so toll finde. Allerdings habe ich (für mich) bis heute noch keinen Anwendungsfall sehen können, warum ich verschiedene Speicherpfade benötigen sollte? Irgendwie torpediere ich damit den Ansatz, dass ich mich darum nicht kümmern muss. Aber das ist ja der Charm an dem System, für andere mag das sehr nützlich sein. 🙂
Herbert
Wenn Du keine benötigst, dann musst du auch keine einrichten 🙂 Man merkt ja selbst, womit man besser fährt. Ich habe ganz gerne ein paar „Häufchen“, z.B. alle Dokumente und Rechnungen, die direkt unser Haus betreffen. Das ist beispielsweise bei mir ein eigener Pfad.
Jan
Eine super Artikelserie, trifft genau meinen Bedarf 👍🏻
Paperless schiebt auch alle konsumierten Originaldokumente in seinen „originals“-Ordner. Dort möchte ich die Original-Dateinamen beibehalten, keine Umbenennung in 0000001.pdf usw
(Wie) geht das? Danke!
Herbert
In der Mitte des 4. Teils bin ich auf genau diese Frage eingegangen: Man kann den Platzhalter {title} verwenden, dann entfällt die 00001.pdf-Nummern-Geschichte und der eigentliche Titel wird übernommen.
Jan
Hmmm ich meinte nicht den „archive“-Ordner, sondern die „originals“.
Speicherpfade und der Platzhalter {title} beziehen sich oben beschrieben doch auf die archivierten Dokumente, nicht auf die Verwahrung der originals? Die sollte m.E. auch original erfolgen, nicht mit umbenannten 001-Dateinamen.
Benny
Das macht Paperless schon Standardmäßig immer so.
Alle Dokumente werden als Original und dann als OCR Variante in oben beschriebenen Varianten gespeichert.
Stefan
Hallo Herbert,
danke für diese super Artikelserie.
Ich habe nicht wirklich was von der Nutzung von Dokumententypen bei dir gelesen. Nutzt du diese? Oder sind diese „Speicherpfade“ inkl. Bezeichnung der Dateien das, was für dich ausreicht?
Vielen Dank,
Stefan
Herbert
Ja – für mich sind die Dokumentenpfade ausreichend. Es gibt Anwender, die sehr sorgfältig alle Felder von Paperless-ngx ausfüllen, sich viele Gedanken um Tags usw. machen. Meine Beobachtung ist: Dieser Aufwand zahlt sich nicht aus, da die Suche von Paperless-ngx hervorragend ist. Ich will es ja nicht „schön ordentlich“ haben – mein Ziel ist: schnell Dokumente aufnehmen, schnell abrufen, schnell finden 🙂
Bernd
Hallo Herbert, das sind sehr gute Artikel. Vielen Dank dafür!
Ich habe einige Fragen/Verständnisprobleme und wäre für Antworten/Aufklärung sehr dankbar 🙂
Den Consumeordner habe ich in der „docker-compose.yml“ so eingerichtet, dass Daten, die in mein Verzeichnis auf dem NAS rein kommen direkt verarbeitet werden.
volumes:
– data:/usr/src/paperless/data
– /home/bdream/paperless:/usr/src/paperless/media
– ./export:/usr/src/paperless/export
– /home/bdream/paperless/consume:/usr/src/paperless/consume
Die verarbeiteten Dateien liegen aber direkt (bei meinem Raspi auf der SD-Card) in den Ordnern „/home/bdream/paperless/documents/archive“ und „/home/bdream/paperless/documents/originals“.
Wenn ich „/home/bdream/paperless/documents/archive“ zu meinem NAS in ein Verzeichnis mounte, funktioniert das nicht. Also, der Mount schon (wenn ich Dateien im NAS oder auf dem Raspberry ablege, sehe ich es im anderen Ort), aber ich habe nach Aufruf von „docker compose exec webserver document_renamer“ keine Dateien mehr im „/home/bdream/paperless/documents/archive“ und nicht auf dem NAS. Das hängt sicherlich mit der Konfiguration in der „docker-compose.yml“ zusammen, oder?
Dann habe ich noch eine Frage zum Tag Posteingang.
Welche Auswirkung hat es, wenn ich das Tag enferne oder auch nicht? Dazu habe ich nichts in der Doku gefunden.
Ist das Einzige, dass dann die konsumierten Daten nicht mehr im Posteingang sind?
Das würde auch beschreiben, warum nach „docker compose exec webserver document_renamer“ die Dateien in der paperless-GUI immer noch die Namen haben, wie zuvor :S
Dateien löschen:
Ich lese einerseits, dass man in paperless keine Dateien löschen soll/darf, da diese ansonsten nicht mehr wiedergefunden werden.
Andererseits lese ich immer wieder, dass man erst mal ausprobieren soll und dann die Dateien löschen soll um dann erneut einen anderen Weg zu probieren. Was ist denn nun richtig?
Vielen Grüße
Bernd
Herbert
Hallo Bernd,
danke für die nette Rückmeldung!
Die Sache hört sich etwas komplex an – versuchen wir mal, uns einer Lösung zu nähern:
1. Du nimmst ein neues Dokument in Paperless-ngx auf, dieses erscheint (nach erfolgter Verarbeitung) auf dem gewünschten (Unter-)Pfad in Deinem /home/bdream/paperless/documents/arichive bzw. originale.?
2. Warum gibst Du zusätzlich einen renamer_Befehl an? Wenn nach einem solchen Befehl etwas anders ist, dann hast Du Parameter in der env oder yml, die z.B. einen anderen Speicherort zuweisen. Aber auch das ist eigentlich egal, denn _innerhalb_ des /home/bdream/paperless/documents/-Verzeichnisses _muss_ sich die Datei immer noch befinden – probier mal den Suchbefehl im Dateimanager des Raspberry Pi .
Zum „Posteingang“: den Tag kannst Du nehmen, behalten, entfernen – sein Hauptzweck ist, auf der Startseite alle letzten Dokumente angezeigt zu bekommen. Nach dem Entfernen „verschwinden“ die Dateien nur im Widget – sie bleiben aber erhalten.
Zum Punkt „Löschen“: Wo steht, dass man keine Dateien in Paperless-ngx löschen darf? Natürlich darf uind soll man – halt über das Backend von Paperless-ngx und nicht direkt z.B. über einen Dateimanager. Es gibt sogar eine Trash-Dir-Variable.
Mach‘ mal zum ersten Punkt folgenden Test:
1. ziehe ein Dokument „x.pdf“ über das Backend zu Paperless-ngx
2. schau‘ dir im Dateimanager bei /home … documents … an, ob es angekommen ist
3. weise probehalber einen Speicherort zu wie „kleinertest“ und schau, ob das Dokument damit auf /home … archive …kleinertest verschoben wurde.
Und noch: Wenn Du die Paperless-ngx – Verzeichnisse auf anderen Systemen spiegelst, dann muss alles so konfiguriert sein, dass diese Systeme _keine_ Änderungen bei den Paperless-ngx vornehmen! (Mit Ausnahme des Consume-Ordner – dort will man über eine solche Verbindung manchmal neue Dateien einfügen.)
Bernd
Vielen Dank für deine Antwort 😀
Ich denke ich habe da noch eine oder zwei Hinrwindungen zuviel verknotet.
Vielleicht arbeite ich auch an zu vielen Problemen gleichzeitig..
Zu 1.
Wenn ich ein Dokument consumieren lasse erscheint es im archive- und originals-Verzeichnis. Aber, wenn ich z.B. das archive auf mein NAS mounte, um die Daten im NAS anstatt auf dem Raspi zu haben, verschwinden die Dateien im Verzeichnis.
Also, die Verarbetung an sich funktioniert schon mal, auch wenn hier noch einiges zu klären ist, um die Dateien so benannt zu bekommen, wie ich das gerne hätte 😉
Zu 2.
ja, der Renamer wird ja nur benötigt, wenn ich an den .env und/oder .yml Änderungen vornehme.
Posteingang und Löschen: Verstehe ich, gkaube ich, muss das noch etwas ausprobieren.
Ich habe überall „automatisch erlernen“ angegeben. Ist das der richtige Weg?
Geht das Erlernte verloren, wenn ich Dateien lösche?
Das System lernt nur besser, wenn mehrere Dokumente eingelesen werden? Oder sollte ich lieber eindeutige Merkmale wie Kundennummer, oder Vertragsnummer hart verdrahten?
Mach‘ mal zum ersten Punkt folgenden Test:
Wie unter Zu 1. das funktioniert nur ohne mount. Da wird das Problem an anderer Stelle liegen ich blicke es aber nicht 🙁
Die Peicherorte habe ich auch über „PAPERLESS_FILENAME_FORMAT=“ angegeben, nicht über den Speicherpfad. Gibt es hier Unterschiede, warum was besser ist oder beides sein sollte?
Das mit dem Konfigurieren ist ggf. schwierig. Die Dateien sollen ja in den Verzeichnissen liegen, dass auch mein Kind mal eben schnell was in der Struktur finden kan, wenn paperless nicht genutzt wird. Also ein Abbild der vor paperless-Zeit 😉
Schönen Abend!
Bernd
Herbert
Auf der Seite von Paperless-ngx scheint alles gut zu funktionieren – die Mount-Sache musst Du Dir bei Deinem anderen System dann noch mal genauer ansehen.
Das mit dem Training funktioniert in der Regel gut – beobachte einfach mal, wie Paperless-ngx die Einordnung vornehmen würde und ob das dann für Dich so passt.
Die Sache mit den Speicherpfaden habe ich in diesem Artikel ja recht genau erklärt. Wenn Du nach diesem Schema vorgehst, erhälst Du auch mit einem „normalen“ Dateimanager genau die Ordnerstruktur angezeigt – so dass auch andere Familienmitglieder ohne Paperless-ngx die Dateien finden können sollten.
Bernd
Hallo Herbert,
ich habe ein Verständnisproblem mit drei Punkten, vielleicht kannst du mich erhellen?
1. Speicherpfade
Der Unterschied zwischen „PAPERLESS_FILENAME_FORMAT“ und „Speicherpfade“ ist mir nicht klar.
Kann ich mit beiden identisches machen?
2. {tag_list}
Die {tag_list}, kann ich die Reihenfolge irgendwie beeinflussen?
3. {title}
Der {title} beinhalten ja den Namen des Dokumentes zum Zeitpunkt des Konsumierens. Richtig?
Wieso wird das nicht geändert, in der Startseite / Dokumentanansicht in Paperless, nachdem Paperless das umbenannt hat? Muss das irgendwo konfiguriert werden?
Vielen Dank!
Bernd
Herbert
1. ja – ich würde bei einer Variante bleiben
2. nein
3. auf der Weboberfläche erscheint jener Titel, den Du in das entsprechende Feld der Metadaten eingeben hast
Max
Lieber Herbert,
Deine Anleitung hier, ist einmalig! So etwas Gutes habe ich sonst nirgends im Internet gefunden – vielen, vielen Dank!
Ich nutze seit 01.01.2024 paperless-ngx.
Auf meiner Festplatte sieht es beispielhaft aus
– Nexcloud
— 1 Dokumente
— 1.1 Ausweise
— 1.3 Finanzen
—- 1.3.1 Steuer
—– 2024
—– 2023
usw.
— 1.4. Briefe
—- Digitaler Briefkasten
—– media
—— documents
——- originals
——– Max
——— Arbeitgeber
———- XY
— 2 Arbeit
— 2.1. Aktuelle Tätigkeit
—- Max
—– 2.1.1 Gehaltsabrechnungen
— Eva
—- 2.1.1 Gehaltsabrechnungen
Vor dem „Digitalen Briefkasten“ habe ich die Unterlagen nach dem Scannen in z.B. 1.3.1 Steuer in das entsprechende Jahr eingeordnet oder die Gehaltsabrechnungen in 2.1.1 Gehaltsabrechnungen in den ensprechenden Jahresordner. Nun steht meine Welt Kopf, da alles automatisch in media in den entsprechenden Ordnern landet. Meine Grundstruktur mit
– Nextcloud
— 1 Dokumente
— 2 Arbeit
— 3 Freizeit
— 4 Privat
— 5 Kinder
— 6 Archiv
ist dahin 🙁 Hier musste man nicht so viel Klicken wie vorher und ist weniger verschachtelt, als wäre als im Ordner „Digitaler Briefkasten“
Hast Du Vorschläge, Ideen bzw. wie würdest Du das machen/machst Du es aktuell?
Kurze zweite Frage:
– Es entstehen in originals leere Ordner, nachdem ich den Speicherpfad geändert habe.
docker-compose exec webserver document_renamer
hilft nicht leere Ordner zu löschen, genauso wenig, wie
docker image prune -a
Hast Du hierfür auch eine Idee?
Vielen, vielen Dank nochmals!
Herbert
Danke für das nette Feedback! Kurz zu Deinen Fragen:
1. Wenn es Dir wichtig ist, so kannst Du die gleiche Ordnerstruktur, die Du in Nextcloud hattest, auch in Paperless-ngx übertragen – also (wie im Artikel beschrieben) „Speicherorte“ zuweisen mit „1 Dokumente“, „1.1 Ausweise“ usw.
2. In Teil 12 der Serie habe ich beschrieben, wie ich für mich die Speicherorte definiere = wenig Aufwand, aber eine Struktur, die auch ohne Paperless-ngx funktioniert.
3. Das mit den „leeren Ordnern“ ist mir bei meinen Tests bisher nicht aufgefallen. Vielleicht fährst Du mal mit der docker-compose down – Anweisung runter und startest neu.
Max Muster
Vielen Dank für Deine extrem schnelle Antwort!
Wie lässt sich mein aktueller media Pfad
volumes:
– $HOME/Nextcloud/1 Dokumente/1.4 Briefe/Digitaler Briefkasten/data:/usr/src/paperless/data
– $HOME/Nextcloud/1 Dokumente/1.4 Briefe/Digitaler Briefkasten/media:/usr/src/paperless/media
– $HOME/Nextcloud/1 Dokumente/1.4 Briefe/Digitaler Briefkasten/export:/usr/src/paperless/export
– $HOME/Public/Scanner:/usr/src/paperless/consume
so verändern, dass die Steuerunterlagen unter
Nextcloud/1 Dokumente/1.3 Finanzen/1.3.1 Steuer
landen?
Für Path habe ich
Finanzen/{owner_username}/{correspondent}/{document_type}/{created_year}-{created_month}-{created_day}-{owner_username}-{correspondent}-{document_type}-{title}
Meines Wissens landet dieser Path als Unterordner von
– $HOME/Nextcloud/1 Dokumente/1.4 Briefe/Digitaler Briefkasten/media:/usr/src/paperless/media
dort weiter mit documents/originals dann Finanzen/{owner_username}/{correspondent}/{document_type}/{created_year}-{created_month}-{created_day}-{owner_username}-{correspondent}-{document_type}-{title}
Nochmals Danke!
Herbert
Nein, so wird es nicht gehen. Jetzt nur in Stichpunkten, da ich das bereits im Artikel ausführlicher beschrieben habe:
1. Paperless-ngx benötigt für seine Dokumente einen „Ausgangsordner“ – bei mir ist das „/home/paperless-ngx“ . Du kannst auch einen definieren wie „/nextcloud-ordner/meine-dokumente“ oder so. Dieser Ausgangsordner enthält den Unterordner „documents“ mit „documents/archive“ bzw. „documents/originals“.
2. ALLE von Dir definierten Speicherorte (Unterordner) findest Du _ausschließlich_ in diesen Ausgangsordnern.
3. Wenn Du also einen Speicherort „Steuer“ definierst mit dem Inhalt „1. Dokumente/1.3 Finanzen/1.3.1 Steuer/{title}“, dann einen Steuerbescheid mit dem Namen „rueckzahlung.pdf“ scannst, diesem den Speicherort „Steuer“ zuweist, dann erscheint dieses Dokument unter
„/home/paperless-ngx/documents/archive/1. Dokumente/1.3 Finanzen/1.3.1 Steuer/rueckzahlung.pdf“
Am einfachsten ist es, Du probierst die Sache mal mit 5 Testdokumenten aus und beobachtest dabei, wie Paperless-ngx auf dem Speichermedium den Pfad anlegt – dann bekommst Du rasch ein Gefühl dafür, wie man das macht.
Andi
Hallo,
ich wollte mal fragen, ob es eine Möglichkeit gibt, ein Benutzerdefiniertes Feld in den Speicherpfad einzubinden?
z.B.:
Korrespondent: ADAC
Ben.def.Feld namens
Vertrag: Auto1 oder Auto2
Speicherort: ….\Unterlagen\ADAC\Auto1\Vertrag.pdf
oder
Speicherort: ….\Unterlagen\ADAC\Auto2\Vertrag.pdf
Bzw.
Korrespondent: Sportstudio
Vertrag: Max oder Maxi oder Anja
Speicherort: ….\Unterlagen\Sportstudio\Max\Vertrag.pdf
oder
Speicherort: ….\Unterlagen\Sportstudio\Maxi\Vertrag.pdf
oder
Speicherort: ….\Unterlagen\Sportstudio\Anja\Vertrag.pdf
Herbert
Aktuell geht es nicht, wurde aber als Feature Request eingereicht.
Justin
Moin,
um mich nicht in zu vielen Pfaden zu verlaufen nutze ich folgende, einfache Speicherlogik:
{{ correspondent }}/{{ created }}_{{ correspondent }}_{{ title }}
Nun ist es mir passiert, dass ich bei der Anlage eines Korrespondenten einen Zifferndreher eingebaut habe. Entsprechend wurde der Ordner inkl. des Drehers angelegt. Den Fehler habe ich leider erst nach der Bearbeitung, also auch nach dem Speichern, von 3 Dokumenten entdeckt. Die Korrektur des Korrespondenten habe ich bereits über das paperless-Menü gemacht. Wie korrigiere ich nun den Order, resp. Dateinamen?
Ich vermute, dass beim nächsten Dokument dieses Korrespondenten ein neuer Ordner mit dem korrekt geschriebenen Namen entstehen wird, und ich dann die 3 alten Dokumente über paperless „umspeichern“ kann?
Bevor ich durch eine vorschnelle manuelle Manipulation irgend was durcheinander bringe, frage ich lieber mal.
VG
Justin
Herbert
Meine Erfahrung ist, dass nachträgliche Änderungen von Paperless-ngx ganz gut aufgefangen werden. Wenn ich einen Speicherort ändere, dann schiebt Paperless-ngx die Dateien in den neuen Ordner. Mach‘ vorher einen Export, führe es dann so aus, wie Du es eigentlich wolltest und im Falle des Falles kannst Du ja einen Import machen, wenn es nicht so ist, wie Du dachtest.
Sebastian
Hallo Herbert,
ich will unbedingt einmal sagen, dass auch mir deine Anleitungen eine enorme Hilfe sind. Fundiert und stets gut nachvollziehbar.
Ich befinde mich im Prozess der Migration (rund 2000 Dokumente) von ecoDMS zu Paperless und dank deiner Beiträge kann ich die dort aufgebaute Struktur nach und nach in Paperless nachbilden, muss auf praktisch nichts verzichten und verstehe auch, was ich da eigentlich mache.
Also ganz herzlichen Dank!
Herbert
Das ist eine sehr nette Rückmeldung! Vielen Dank dafür! Du wirst sehen: Der Umzug lohnt sich wirklich und wird Dir im Alltag einiges an Erleichterung bringen.
Alexander Ruthmann
Hallo Herbert,
vielen Dank für die sehr ausführlichen Artikel über Paperless, das hat mir schon sehr geholfen. Leider habe ich festgestellt, dass bei mir das mit den Speicherpfaden nicht so funktioniert, wie du es beschreibst.
Erst einmal habe eich Paperless so konfiguriert, dass der bestehende Dateiname immer als Titel des Dokuments genutzt wird und der Dateiname immer aus dem Titel abgeleitet werden soll.
Dann habe ich einen Speicherpfad angelegt, der jede Datei Anhand des Ausstellungsdatums in einen Unterordner mit dem Jahr legen soll und der Dateiname aus dem Titel bestehen soll: {{ document_date_year }}/{{ title }}.
In einigen Fällen funktioniert das auch. Das Ausstellungsdatum wird korrekt gesetzt und der Dateipfad wird in der Übersicht korrekt angezeigt, und die Datei liegt im Unterordner mit dem original Dateinamen.
In vielen Fällen funktioniert es aber auch nicht und die Datei liegt im documents/archive, bzw. documents/originals und hat eine Nummer als Dateinamen, obwohl das Ausstellungsdatum korrekt gesetzt ist.
Wenn ich dann in der Web-UI den Dateipfad anpasse, bleibt die Datei wo sie ist und es wird nur in der DB ein neuer Dateiname geschrieben, aber es wird keine Änderung am Dateisystem vorgenommen und keine Datei verschoben.
Ich nutze eine Docker-Instanz von Paperless-ngx 2.17.1.
Hast du eine Idee, woran das so unterschiedliche Verhalten liegen kann?
Liebe Grüße
Alex
Herbert
Hm, schwer zu sagen – bei mir funktioniert es reibungslos, einschließlich verschieben von Dateien. Hast Du die Befehle für reindex angewandt und docker auch mal gestoppt und neu gestartet nach Änderungen? Was sagen die Protokolle?
Chris
Hallo!
Erstmal Danke für diese tolle Sammlung zu Paperless! Eine wahre Fundgrube an Ideen und Tipps. 🙂
Wo ich ein bisschen struggle ist noch mit dem Dokumentenimport und den Spreicherpfaden.
Mein Ziel wäre es, wenn die Pfade der Dateien im „Consume“-Ordner 1:1 als relative Pfade übernommen werden könnten. Das scheint aber – soweit ich das verstehe – nicht ohne weiteres möglich zu sein, da es kein Placeholder {{ original_filepath }} oder so gibt.
Bei den Speicherpfaden scheint ja keine Zuweisung über Tags möglich zu sein, was ich sehr schade finde, da die Dateien durch dem Importer ja bereits Tags der ursprünglichen Ordner bekommen. So könnte man sich einfach Speicherpfade bauen, die zu den jeweiligen Tags passen.
Meine halbgare Lösung im Moment ist, dass ich {{ if }} und {{ elif }}-Definitionen in der ENV-Variable PAPERLESS_FILENAME_FORMAT habe. Das ist aber sehr unschön und ich müsste für jeden Tag und zusätzlichen Ordner eine weitere Kaskade da manuell einbauen.
Wie bekomme ich folgendes hin:
– Dokumente werden anhand von Tags automatisch in unterschiedliche Speicherpfade geschrieben.
– Dabei soll ein genauer Match nötig sein, also z,B. nur wenn die Tags „Bank“ und „Kontoauszüge“ und „ING“ soll es nach „Bank/ING/Kontoauszüge/…“ gespeichert werden.
– Da Ganze soll schon beim Import über den Consumer klappen.
Geht das? Irgendwie stehe ich gerade auf dem Schlauch, denn bei mir wird das irgendwie nicht getriggert.
Danke schonmal für die Tipps!
Viele Grüße
Chris
Herbert
Könnte gehen – habe ich aber noch nicht probiert. Wenn, dann „Arbeitsabläufe“, bei Auslöser „Dokument aktualisiert“, dann „Tag“ auswählen (für die UND-Verknüpfung von Tags evtl. mehrere Auslöser definieren. Unter den dazugehörigen Aktionen Aktionstyp „Zuordnung“ wählen – dort kannst du den gewünschten Speicherpfad auswählen. Musst wahrscheinlich etwas rumprobieren. – Ich persönlich automatisiere in Paperless-ngx nicht sehr viel, da ich lieber „von Hand“ den Überblick behalten möchte. Aber mein wöchentliches Archivaufkommen ist – nach der Ersteinrichtung – auch recht gering. Da hätte ich kaum einen Zeitgewinn von zu komplexen Abläufen. – Jedenfalls probier mal und melde Dich, ob es mit Arbeitsabläufen klappt.
Rene
Hallo,
ich arbeite mich durch die einzelnen Artikel und habe wieder eine Frage.
Installiert wie im Beitrag 5 beschrieben, auch mit der Angabe der Ordner. Unter paperless-ngx habe ich die Ordner consume, export und die beiden docker-compose Dateien.
Wie in Teil 8 beschrieben, lasse ich mir ein Backup erzeugen „sudo docker compose exec -T webserver document_exporter ../export -z“ Im Archivordner landen die ganzen Dateien, aber nicht in einer Ordnerstruktur. Die unter Speicherpfade angelegte Struktur habe ich jetzt unter
/mnt/dietpi_userdata/docker-data/volumes/paperless_media/_data/documents/archive gefunden. Dort liegen die Testdateien z.B. unter /mnt/dietpi_userdata/docker-data/volumes/paperless_media/_data/documents/archive/Haus/Wasser.
Kann man diesen Pfad auch unter paperless-ngx neben consume und export legen oder den Export anpassen, dass die Ordnerstruktur mit Übertragen wird?
Vielen Dank
Herbert
Der Export-Befehl hat eine andere Aufgabe – er soll gerade nicht die Ordnerstruktur abbilden, aber nach einem Import ist die Ordnerstruktur wieder da – Zur anderen Frage: Du hast Dein Paperless-ngx etwas anders installiert, als ich es empfohlen habe. Du musst dann Dein Media-Verzeichnis an einen anderen Ort verbiegen, danach kann man auch die Unterordner sichern.
Dennis
Hey erstmal vielen Dank für deine tollen Blogposts. Ohne die hätte ich bis heute kein Paperless. Ich versuche in meiner neuen Paperless Instanz etwas Ordnung zu schaffen und würde gerne nach Owner trennen. Also Ich/Frau/Sohn1/Sohn2 etc. sollen ihre eigenen Ordner bekommen in denen dann die weiteren Unterordner folgen.
Dazu wollte ich es mir einfach machen und mit folgendem Pfad arbeiten: {{ owner.username }}/{{ correspondent }}/{{ created_year }}/{{ document_type }}/{{ title }}
Leider meldet mir Paperless immer „Ungültige Variable erkannt“ ohne weitere Details. Was könnte hier das Problem sein? Paperless NGX läuft bei mir als Synology Docker.
Herbert
Danke für die nette Rückmeldung! Hm, ich muss diese Variante mal bei Gelegenheit ausprobieren, vielleicht kann ich Dir dann einen Tipp geben.