Papra – der kleine Bruder von Paperless-ngx
In der Artikelserie zu Paperless-ngx (bisher 20 Teile) habe ich gezeigt, dass dieses System zur Dokumentenverwaltung sehr viele Möglichkeiten hat – aber auch, dass es mit einem gewissen Einarbeitungs- und Pflegeaufwand verbunden ist. Papra verfolgt einen ähnlichen Ansatz, ist aber deutlich reduzierter. Das Programm ist noch jung, wird aber intensiv entwickelt. Die Erfahrungen mit der aktuellen Beta-Version 0.6.3 sind gut, das Programm lief stabil und flott.

Inhalt
Was unterscheidet Papra von Paperless-ngx?
Paperless-ngx ist ein typisches DMS (Dokumentenmanagementsystem), das zur systematischen Verwaltung von wichtigen Dokumenten dient. Dafür stehen zahlreiche Meta-Felder zur Verfügung, komplexe Suchvorgänge können durchgeführt werden, Abläufe mit Wenn-Dann-Bedingungen kombiniert werden usw. Papra ist – absichtlich – bescheidener. Einfach gesagt: Man nimmt Dokumente auf und erhält auch bei großen Datenmengen eine außerordentlich flotte Volltextsuche. Organisieren kann man via Tags und durch getrennte Verwaltung unterschiedlicher Dokumentenarchive. Das ist – fast – schon. Damit würde ich Papra eher als Literaturverwaltung denn als DMS bezeichnen.
Warum dann nicht einfach bei der Suche via Dateimanager bleiben?
Der wichtigste Unterschied zu den Suchmöglichkeiten der Betriebssysteme: Papra ist eine Anwendung für den Homeserver (ich habe das System auf einem Raspberry Pi 4 installiert). Damit kann man Papra von jedem Gerät in der Familie aufrufen und nach Dokumenten suchen – egal, ob Notebooks, Tablets oder Smartphones. Und durch die 1-Klick-Wireguard-Möglichkeiten von Fritzbox & Co. steht mir der gesamte Datenbestand via VPN auch unterwegs in Zug und Hotel zur Verfügung.
Abgesehen davon: Je nach Betriebssystem und Hardware kann eine Volltextsuche in großen Datenbeständen quälend langsam sein – bei Windows war ich damit nie zufrieden.
Besonders leichte Installation
Die Installation von Paperless-ngx ist zwar auch nicht besonders schwierig, aber bei Papra genügt eine Zeile, sofern man Docker auf seinem System bereits eingerichtet hat:
docker run -d --name papra -p 1221:1221 ghcr.io/papra-hq/papra:latestNach wenigen Sekunden kann so Papra von jedem Gerät aus erreicht werden, indem man die IP seines Homeservers einträgt und um Port 1221 ergänzt – z. B. „192.168.178.182:1221“. Fertig.
Aufnahme von Dokumenten

Dokumente können via Drag-and-Drop oder per Import-Button hinzugefügt werden. Es ist aber auch möglich, Ordner von Papra überwachen zu lassen. Alle Dokumente, die sich in diesen Ordnern befinden oder später – z. B. via Scanner – hinzugefügt werden, werden automatisch ins Dokumentenarchiv aufgenommen.
Arten von Dokumenten und Texterkennung
Noch ist bei Papra nicht alles implementiert, aber problemlos verarbeitet werden PDF-Dateien, die bereits über einen Textlayer verfügen. Papra hat zwar bereits die OCR-Funktion für Bilder (PNG, JPG) eingebaut, für PDF-Dokumente soll die Erkennung in einer der nächsten Versionen kommen.
Für mich ist dieser Punkt nicht besonders wichtig, da ich auch bei Paperless-ngx auf die OCR-Funktion via Anwendung verzichte – Dokumentenscanner und Smartphone integrieren bereits bei der Erfassung Textlayer perfekt, bei digitalen Anhängen ist das meist ohnehin der Fall. Alle Test-PDFs wurden vollständig in den Index von Papra übernommen.

Die Texterkennung in Bildern ist solala. Mit Umlauten gibt es wohl noch ein Problem, liegt aber vielleicht auch nur an der Konfiguration.

Die Erkennung von MS-Office-Dokumenten und EPUBs soll in einer der nächsten Versionen kommen.
Prinzipiell können auch E-Mails bzw. deren Anhänge eingelesen werden können, das habe ich aber nicht ausprobiert.
Organisationen = Sammlungen
Der Begriff „Organisationen“ klingt etwas merkwürdig, da man zuerst an Firmen usw. denkt. Gemeint ist damit, dass man beliebig viele getrennte Dokumentensammlungen erstellen kann.

Auf diese Weise werden z. B. beim einem Suchvorgang nur die Dokumente der aktuellen Organisation einbezogen.
Suchergebnisse
Dazu gibt es nicht viel zu sagen: Man beginnt, in das Suchfeld zu tippen, die Suche beginnt sofort, mit jedem neuen Buchstaben verändert sich die Liste:

Tag-Filterung
Alle Dokumente, die einen bestimmten Tag aufweisen, kann man per Klick auf einen Tag auswählen. Entweder direkt beim aktuellen Dokument – oder über die Seitenleiste. Die Tags können Beschreibungen und Farben erhalten:
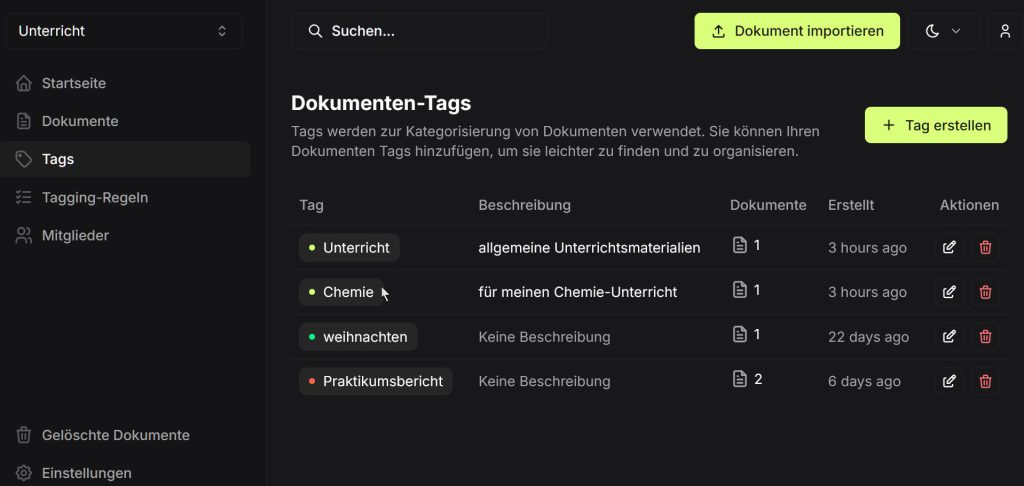
Automatisierungen für Tags
Tags spielen bei Papra eine wichtige Rolle. Daher gibt es die Möglichkeit, automatisch Tags vom System zuweisen zu lassen. Dazu definiert man Tagging-Regeln nach dem Prinzip: „Wenn im Dateinamen oder im Text die folgenden Stichwörter vorkommen – dann vergib den Tag XYZ.“

Überwachte Ordner
Für jede Sammlung/Organisation lassen sich Dateiverzeichnisse konfigurieren. Die Dateien, die sich in diesem Verzeichnis befinden, werden automatisch ins Archiv übernommen. Werden neue Dateien dort gespeichert, so erkennt das Papra und „saugt“ auch diese auf. Konfiguriert werden kann, ob die Dateien im ursprünglichen Verzeichnis erhalten bleiben oder dort gelöscht werden sollen.
Für die Einrichtung trägt man in die YML-Textdatei Ordner und Organisations-ID ein. Klingt ein wenig kompliziert, hat bei meinen Tests aber problemlos geklappt. Eine ausführliche Anleitung dazu gibt es in der Dokumentation von Papra.
Fazit
Es gibt noch eine Reihe weiterer kleiner Funktionen, die ich für diesen Überblick übersprungen habe. Wie gesagt: Die Anwendung befindet sich eigentlich noch im Beta-Stadium, ist aber schon jetzt recht brauchbar. Auf meinem Raspberry Pi 4 (mit 4 GB) läuft Papra sehr flott. Wer nicht die umfangreichen Funktionen von Paperless-ngx benötigt, erhält mit Papra ein System mit einem deutlich geringeren Pflegeaufwand. Zudem: Ich habe es durch Paperless-ngx sehr zu schätzen gelernt, dass ich von jedem Gerät und insbesondere auch absolut problemlos von unterwegs sicher auf meine Dokumente zugreifen kann. Wenn man mal eine Versicherungsnummer nicht zur Hand hat – kurz das Smartphone zücken, Stichwort eingeben – und kawumm! – das Dokument ist da. Das funktioniert genauso gut mit Papra. Also: Einfach mal testen – ist ja mit einer Code-Zeile installiert.




8 Kommentare
Rainer Deckers
Ich konnte wie erwartet papra ohne Probleme installieren. Beim Aufruf über den Webbrowser bekomme ich eine Anmeldeseite und kann mich weder einloggen, noch registrieren. Was mache ich falsch?
Herbert
Auf der Anmeldeseite gibt es einen Registrierungs-Menüpunkt – den anklicken und gewünschte Daten eintragen. Siehe: https://youtu.be/r3DdVXZ06Ho?si=SGm9dlLLWctOQU2j&t=1575
HKaufmann
Bekomme im Webbrowser nur Fehlermeldung das die Seite nicht erreicht werden kann.
„Firefox kann keine Verbindung zu dem Server unter localhost:1221 aufbauen.“
Leider ist das Video nur in Englisch. Es werden nicht alle Videos von Youtube mit einem Übersetzungtools versehen.
Herbert
Hast Du mit docker compose installiert? Ganz gut erklärt ist das in der Dokumentation: https://docs.papra.app/self-hosting/using-docker/ Sofern Englisch ein Problem ist – die meisten Browser bieten eine automatische Übersetzung an, die vielleicht ausreichend ist.
Eberhard Kühne
Ihre Artikel sind eine echtes highlite, Danke! Auch die Grafiken sind Leckerbissen.
Seit ein paar Wochen habe ich Windows den Rücken gekehrt und habe Linux mint 22.2 installiert.
Inspiriert von Ihrem Artikel zu papra habe ich erfolgreich Docker installiert und es läuft.
Aber Ihre Installationszeile zur Installation und zum Start von papra führt zu keinem Erfolg. Papra wird installiert und auch angezeigt aber die Webseite unter localhost Port 1221 ist nicht erreichbar.
Haben Sie eine Idee, wo ich suchen könnte?
Herzliche Grüße
Eberhard
Herbert
Danke für die nette Rückmeldung! Hm, man könnte mal probieren mit „docker ps“ zu schauen, ob der Container korrekt läuft samt Port.
Daniel
Hallo Eberhard,
ist zwar jetzt schon eine Zeit her, aber vielleicht hilft dir das. Ich hatte dasselbe Problem. Ein Blick in Status (‚docker ps‘) und Logs (‚docker logs papra‘) hat gezeigt, dass die Anwendung nur extrem kurz lief (deswegen kein Fehler), dann aber sofort abstürzt und neu startet –> Endlosschleife, hat im Hintergrund ordentlich Ressourcen gefressen…
Grund: Der Container startete nicht, weil in dem kurzen Befehl (der übrigens von Papra direkt stammt) kein gültiger AUTH_SECRET gesetzt wird.
Lösung:
1. In Powershell via ‚cat /proc/sys/kernel/random/uuid‘ einen zufällig secret Key erzeugen (da sollte so etwas herauskommen: fb368d4bf6a74d0caa03c915440e0a1a)
2. Alten Container zerstören (‚docker rm -f papra‘)
3. Dann Papra mit AUTH_SECRET + korrekter URL mit diesem Befehl neu starten (einsetzen von IP und AUTH SECRET nicht vergessen):
docker run -d \
–name papra \
–restart unless-stopped \
-p 1221:1221 \
-e APP_BASE_URL=http://[DEINE LOKALE SERVER IP]:1221 \
-e AUTH_SECRET=[HIER DEN ERZEUGTEN KEY EINGEBEN] \
ghcr.io/papra-hq/papra:latest
Danach sollte es laufen.
Hinweis: So hat es bei MIR funktioniert; keine Garantie, dass es woanders auch so geht…tatsächlich hat ChatGPT bei der Fehlersuche Wunder bewirkt 😉
Grüße
Daniel
Daniel
Super Hinweis und Übersicht, vielen Dank! Ich habe mich davon inspirieren lassen und Papra ausprobiert. Um etwas zurückzugeben, möchte ich zwei für mich ausschlaggebende Punkte ergänzen:
1. Es gibt noch nicht viel Doku zu Papra. Bei Problemen konnte mir ChatGPT bei paperless-ngx sehr viel besser weiterhelfen, weil es einfach mehr Informationen gibt (für mich als Anfänger sehr relevant, für Profis wahrscheinlich weniger)
2. Papra bietet (noch) keine Möglichkeit, Dokumente mit den richtigen Dateinamen versehen in eine „menschen-lesbare“ Ordnerstruktur zu speichern. Wenn es also Papra irgendwann nicht mehr gibt (und das Risiko ist imho deutlich höher als bei paperless), hat man kaum eine verwertbare Datenbasis. Der Entwickler hat angekündigt, dass es das geben wird – aktuell ist halt noch nicht so weit.
Ansonsten wäre Papra aufgrund der Schlankheit und des modernen responsiven Design (und der angekündigten nativen App) für mich die bessere Wahl. So werde ich lieber noch etwas warten, wie es sich weiter entwickelt.
Grüße
Daniel